Knowing-How vs. Knowing-That
Philosophers have long recognized the difference between two types of knowledge: knowing-how and knowing-that, where (roughly and very informally) the former is typically associated with skills and abilities, and the latter is associated with propositions (truths/established facts). In our everyday discourse we use the word ‘know’ for both types of knowledge, which creates some confusion. So, for example, we say things like:
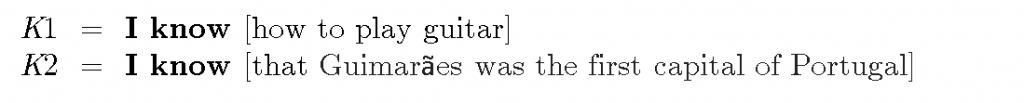
But there are several fundamental differences between K1 and K2, some of which are listed in the diagram below:
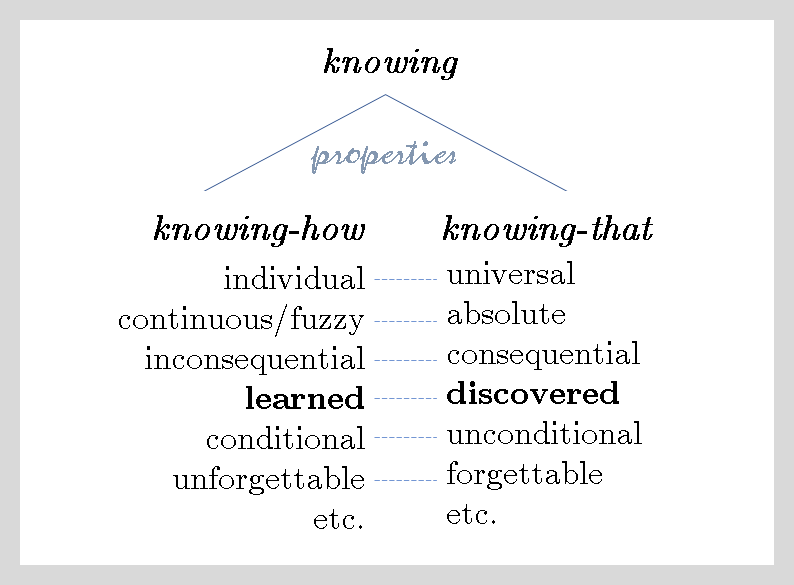
Below we discuss in some details these opposing properties as they relate to K1 and K2 given above.

Finally, skills are not forgettable — we might have some biological and/or brain damage that makes us ‘lose’ (not forget) some skill/ability, but recovery from that damage immediately brings back that skill and no ‘learning’ (training) from scratch will be needed. Propositional facts might however be forgotten (I might forget what is the height of Mount Everest, or what is Bayes’ formula, etc. but again, I do not acquire it back by learning, but by being told again (i.e., reminded).
Below are some examples of both types of knowledge:
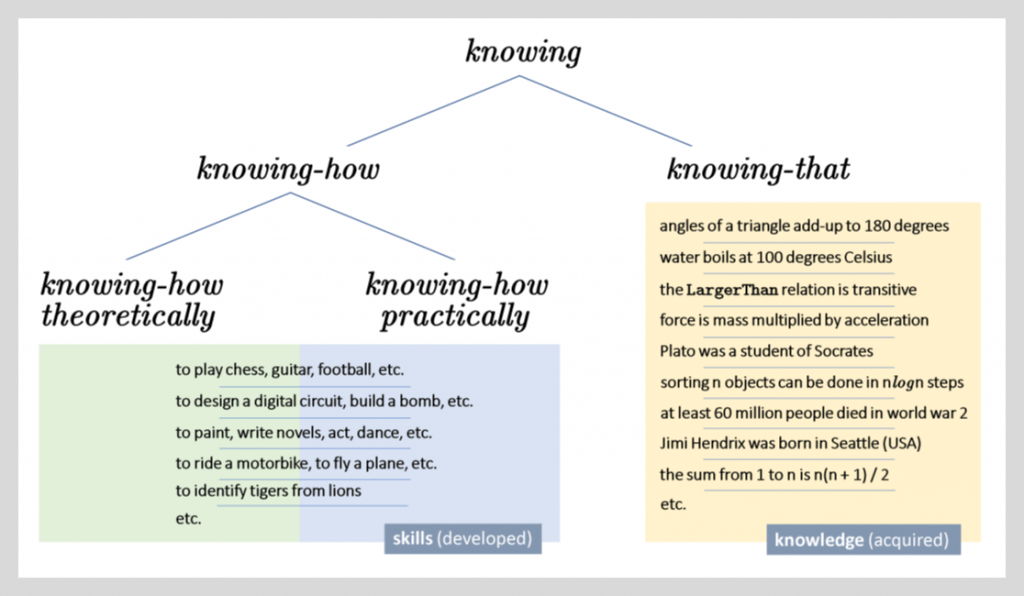
Clearly, then, learning applies to knowing-how and does not even apply to knowing-that. More crucially, most of the knowledge that matters to how the universe works is knowledge that is not learned (from experience, trial and error, from observation/data, etc.) because we are not allowed to learn it differently — it is in fact knowledge that is either discovered, or deduced, or knowledge that is acquired by instruction (i.e., by being told by those that have acquired that knowledge). In fact, this why it sounds awkward to say ‘I don’t know [some-fact]’ while it sounds very natural when I state that ‘I don’t know [how-to]’ and that is because I-do-not-know(established-fact) is not sensible:

Machine Learning or Knowledge Acquisition
I really don’t know how do Machine Learning (ML) enthusiasts ignore the above facts about knowledge — I guess John McCarthy was right when he suggested that computer scientists should read and listen to what philosophers say. If most of the knowledge that really matters in building intelligent machines that can reason and make decisions in dynamic and uncertain environments is acquired and not learned, then it is clearly absurd to ignore ‘knowledge acquisition’ and suggest that ML suffices to get to AGI.
Techniques for effective Knowledge Acquisition must be developed —yes, it is a difficult problem, as the process of manually feeding handcrafted knowledge into a ‘knowledge base’ is not scalable. But problems are not solved by being ignored. It is perhaps one of the biggest challenges in AI, and it is for this reason that I think this is where attention should be given.
Let me end with a simple example that connects where machine learning might happen, where it stops and where knowledge acquisition might pick up and take over. Consider the image below
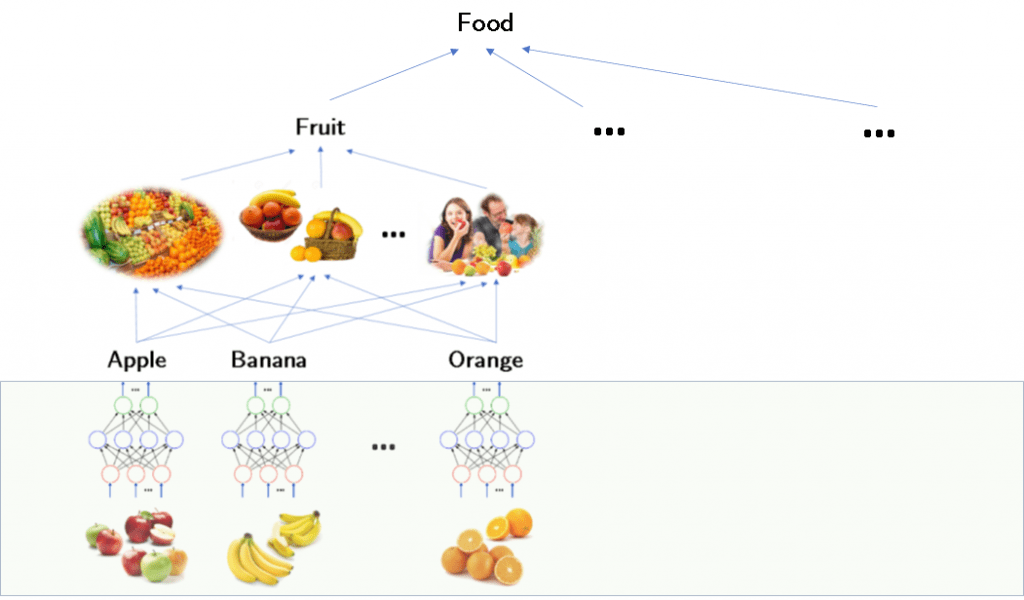
Assuming we have very robust (deep) neural networks (DNNs) that can learn a concept like ‘apple’ — by observing similarities in their patterns. Suppose that process resulted in recognizing images that we labeled (in our semantic memory) as Apple, Banana, and Orange. Something like this must be happening in the early years of a child — images are recognized, by something like a DNN, and they are given a label by the parent that the child (perhaps) stores in semantic memory. But what about the next level? The level at which we group these objects into a higher category? Clearly, we categorize these concepts under the concept Fruit for some reason. Perhaps because we see (instances of) these objects in the same contexts: they are usually found together in a basket (in the kitchen or on the dining table); they seem to be put together on the same shelves in a supermarket, we see people eating them interchangeably, etc. In other words, it seems that they somehow belong to one category. This type of knowledge cannot be learned — the process I just described is a complex reasoning process that is not data-driven. Note: not surprisingly, we might make a mistake in recognizing an orange — since that skill is not binary, but once we know that it is an orange (or not) the fact that it is a fruit (or not) is now a binary decision. Amazing how systematic our reasoning is!
Machine learning is important at the data-level — where we use our sensory inputs to recognize patterns and cognize of first-level objects— but what we know is a lot more and most of what matters is knowledge that is NOT learned but is knowledge that is acquired either by discovery or deduction or by being told.




