Ready to learn Machine Learning? Browse Machine Learning Training and Certification courses developed by industry thought leaders and Experfy in Harvard Innovation Lab.
Fast.ai offers a free online course on Deep Learning and they offer two parts in their course:
- Deep Learning Part 1: Practical Deep Learning for Coders
- Deep Learning Part 2: Cutting Edge Deep Learning for Coders
After those courses, you may be ready to tackle Hinton’s Neural Networks for Machine Learning. Hinton’s course is relatively harder compared to previously mentioned courses since the lectures are quite dry and they contain more Math concepts. If you feel like you cannot tackle the course yet, don’t get discouraged! Leave it for a while and do the Math part (described in next section) and then come back. You will be able to definitely tackle the course this time! Remember, determination, determination and yes, more determination.
Math
Deep Learning definitely requires you to have a strong command of Linear Algebra, Differential Calculus and Vector Calculus, just to name a few. If you want to quickly brush up some elementary Linear Algebra and start coding, Andrej Karpathy’s Hacker’s guide to Neural Networks is highly recommended. I find hadrienj’s notes on Deep Learning Book extremely useful to actually see how underlying Math concepts work using Python (Numpy). If you like to learn from videos, 3blue1brown has one of the most intuitive videos for concepts in Linear Algebra, Calculus, Neural Networks and other interesting Math topics. Implementing your own CPU-based backpropagation algorithm on a non-convolution based problem is also a good place to start to truly understand how backpropagation works.
Getting Serious
If you want to take a notch up your Machine Learning knowledge and ready to get serious (I mean graduate-level serious), dive into Learning From Data by Caltech Professor Yaser Abu-Mostafa. Be prepared to do all the Math. It can be a bit challenging but it will definitely be rewarding once you have gone through it and did your work. I believe it would be hard for textbooks to capture the current state of Deep Learning since the field is moving at a very fast pace. But the go-to textbook would be Deep Learning Book by Goodfellow, Bengio, and Courville. It is freely available online so you might as well download chapter by chapter and tackle the textbook one chapter at a time.
Papers, papers, papers, oh dang it I can’t catch ’em up anymore
Yeah, the knowledge of deep learning comes primarily from papers and the rate at they are being published is extreme these days. A good starting point is Reddit. Subscribe to /r/machinelearning and /r/deeplearning. I find machinelearning subreddit more useful though. ArxivSanity is a good place to check out papers which are related to the ones you are looking for. One important thing to do when reading papers in Deep Learning is doing a good literature review. Doing a good literature review gives you a good sense of how things evolve. A way to tackle doing literature review is to install Google Scholar Chrome Extension and search for the paper you want to look up. You can follow the “Related articles” and “Cited by” to follow the prior work as well as newer work based on that paper. A good habit to form when reading a paper is to draw a mind map of the concepts in the paper.
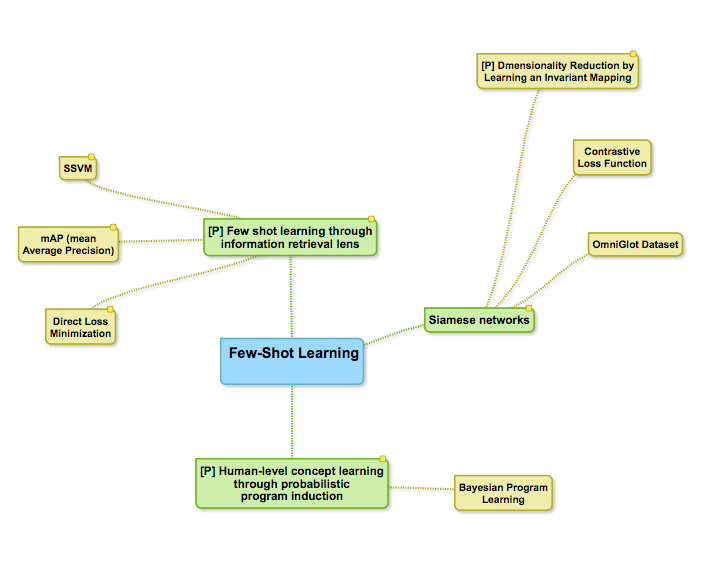
I drew this mind map when I read a paper on few-shot learning [1]— drawn with SimpleMind Lite
The advantage of a mind map is that it is a good way to keep track of the relationships of concepts presented in the paper. I find mind maps very useful to keep track of related literature and how they relate to the paper I am reading. Mind maps give me a clear picture of a paper and also serves as a good summary of the paper after I have read it.
I find Twitter very useful to follow Machine Learning and Deep Learning research. You can start by following well-known individuals in the ML/DL field and branch out from there. As I usually retweet researches on Adversarial Machine Learning and on self-driving cars, you can also follow me on twitter and treat as your feed. What you can do is check out the people whom I have retweeted, check out their tweets and follow other researchers in their circles. Twitter will also recommend good people to follow once you have provided enough data, i.e. followed enough ML/DL researchers (ML FTW!).
Kaggle
I cannot stress how useful Kaggle is. I highly recommend trying out Kaggle competitions even though you have a slim chance of even getting to top-100. The value of Kaggle competitions is the community. Read the kernels and take good practices from them. Read comments and engage in discussions. That’s where you will learn tremendously. You will learn how people do Exploratory Data Analysis and how they handle various cases of missing data, skewed data, etc. You will also learn how people make decisions on why they chose certain models over the other. There is so much knowledge in Kaggle competitions.
Inspirations
Visual Introduction to Machine Learning is a good way to visually grasp how statistical learning techniques are used to identify patterns in data.
Google’s Seedbank is a great resource to get inspired! Take a look at the examples and follow the literature.
Distill.pub is a good place to learn some of the DL concepts interactively. I wish Distill has more articles than it has now.
Tip of the Iceberg
Nothing matters unless you implement what you have learnt yourself. ML and DL sound like magic until you implement the whole pipeline yourself. The whole pipeline includes Data Sourcing, Data Collection, Data Quality Assessment, Data Cleaning, Data Annotation, Data Preprocessing, Building Workflow, Building Models, Tuning Models, Assessing Models, Deploying Models and Reiterating Models. Those steps are just some of the steps in the whole ML/DL pipeline. Those who have done full-scale DL work knows how important it is to keep the whole development operations as streamlined as possible. Not only the whole data sourcing, collection, annotation, cleaning and assessing steps take at least 60% of the whole project, but also they can be one of the most expensive parts of the project (aside from your power-hungry GPUs!).
All in all, ML/DL field is a growing field and you have to keep your ears, eyes, and mind wide open. Don’t just jump onto a shiny new technique just because a paper/blog/tutorial/person/YouTube video says it performs very well on a particular dataset. I have seen a lot of shiny new techniques come and go quite quickly. Always be aware of the fact that it is important to distinguish signal from noise!


