Integration and interdisciplinarity are the cornerstones of modern science and industry. One of the examples of recent attempts to combine everything is the integration of computer vision and natural language processing (NLP). Both these fields are one of the most actively developing machine learning research areas. Yet, until recently, they have been treated as separate areas without many ways to benefit from each other. It is now, with the expansion of multimedia, researchers have started exploring the possibilities of applying both approaches to achieve one result.

Multimodal world and semiotics
The most natural way for humans is to extract and analyze information from diverse sources. This conforms to the theory of semiotics (Greenlee 1978) — the study of the relations between signs and their meanings at different levels. Semiotic studies the relationship between signs and meaning, the formal relations between signs (roughly equivalent to syntax) and the way humans interpret signs depending on the context (pragmatics in linguistic theory). If we consider purely visual signs, then this leads to the conclusion that semiotics can also be approached by computer vision, extracting interesting signs for natural language processing to realize the corresponding meanings.
Computer Vision and its relation to NLP
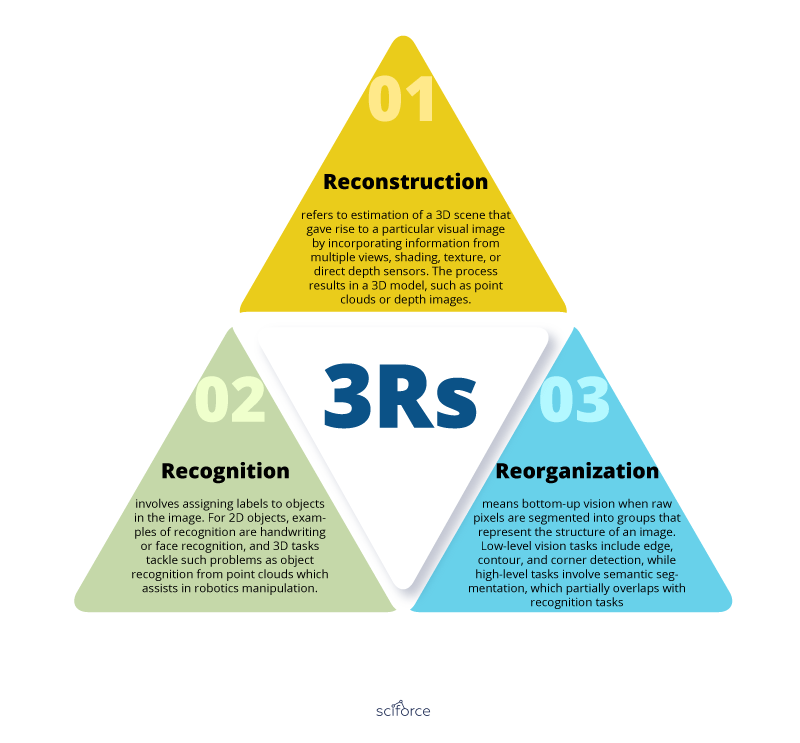
Malik summarizes Computer Vision tasks in 3Rs (Malik et al. 2016): reconstruction, recognition, and reorganization.
Reconstruction refers to the estimation of a 3D scene that gave rise to a particular visual image by incorporating information from multiple views, shading, texture, or direct depth sensors. The process results in a 3D model, such as point clouds or depth images.
Recognition involves assigning labels to objects in the image. For 2D objects, examples of recognition are handwriting or face recognition, and 3D tasks tackle such problems as object recognition from point clouds which assists in robotic manipulation.
Reorganization means bottom-up vision when raw pixels are segmented into groups that represent the structure of an image. Low-level vision tasks include edge, contour, and corner detection, while high-level tasks involve semantic segmentation, which partially overlaps with recognition tasks.
It is recognition that is most closely connected to language because it has the output that can be interpreted as words. For example, objects can be represented by nouns, activities by verbs, and object attributes by adjectives. In this sense, vision and language are connected by means of semantic representations (Gardenfors 2014; Gupta 2009).
Natural Language Processing and its relation to Computer Vision
NLP tasks are more diverse as compared to Computer Vision and range from syntax, including morphology and compositionality, semantics as a study of meaning, including relations between words, phrases, sentences, and discourses, to pragmatics, a study of shades of meaning, at the level of natural communication.
Some complex tasks in NLP include machine translation, dialog interface, information extraction, and summarization.
It is believed that switching from images to words is the closest to machine translation. Still, such “translation” between low-level pixels or contours of an image and a high-level description in words or sentences — the task known as Bridging the Semantic Gap (Zhao and Grosky 2002) — remains a wide gap to cross.
Scope of Integration of Computer Vision and NLP
The integration of vision and language was not going smoothly in a top-down deliberate manner, where researchers came up with a set of principles. Integrated techniques were rather developed bottom-up, as some pioneers identified certain rather specific and narrow problems, attempted multiple solutions, and found a satisfactory outcome.
The new trajectory started with an understanding that most present-day files are multimedia, that they contain interrelated images, videos, and natural language texts. For example, a typical news article contains a written by a journalist and a photo related to the news content. Furthermore, there may be a clip video that contains a reporter or a snapshot of the scene where the event in the news occurred. Language and visual data provide two sets of information that are combined into a single story, making the basis for appropriate and unambiguous communication.
This understanding gave rise to multiple applications of an integrated approach to visual and textual content not only in working with multimedia files but also in the fields of robotics, visual translations, and distributional semantics.
Multimedia files
The multimedia-related tasks for NLP and computer vision fall into three main categories: visual properties description, visual description, and visual retrieval.
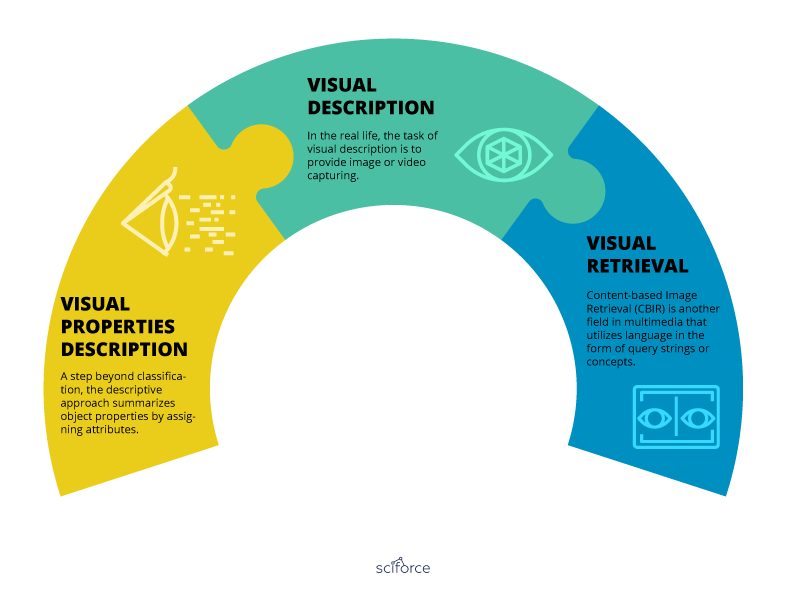
Visual properties description: a step beyond classification, the descriptive approach summarizes object properties by assigning attributes. Such attributes may be both binary values for easily recognizable properties or relative attributes describing a property with the help of a learning-to-rank framework. The key is that the attributes will provide a set of contexts as a knowledge source for recognizing a specific object by its properties. The attribute words become an intermediate representation that helps bridge the semantic gap between the visual space and the label space.
Visual description: in the real life, the task of visual description is to provide image or video capturing. It is believed that sentences would provide a more informative description of an image than a bag of unordered words. To generate a sentence that would describe an image, a certain amount of low-level visual information should be extracted that would provide the basic information “who did what to whom, and where and how they did it”. From the part-of-speech perspective, the quadruplets of “Nouns, Verbs, Scenes, Prepositions” can represent meaning extracted from visual detectors. Visual modules extract objects that are either a subject or an object in the sentence. Then a Hidden Markov Model is used to decode the most probable sentence from a finite set of quadruplets along with some corpus-guided priors for verb and scene (preposition) predictions. The meaning is represented using objects (nouns), visual attributes (adjectives), and spatial relationships (prepositions). Then the sentence is generated with the help of the phrase fusion technique using web-scale n-grams for determining probabilities.
Visual retrieval: Content-based Image Retrieval (CBIR) is another field in multimedia that utilizes language in the form of query strings or concepts. As a rule, images are indexed by low-level vision features like color, shape, and texture. CBIR systems try to annotate an image region with a word, similarly to semantic segmentation, so the keyword tags are close to human interpretation. CBIR systems use keywords to describe an image for image retrieval but visual attributes describe an image for image understanding. Nevertheless, visual attributes provide a suitable middle layer for CBIR with an adaptation to the target domain.
Robotics
Robotics Vision: Robots need to perceive their surrounding from more than one way of interaction. Similar to humans processing perceptual inputs by using their knowledge about things in the form of words, phrases, and sentences, robots also need to integrate their perceived picture with the language to obtain the relevant knowledge about objects, scenes, actions, or events in the real world, make sense of them and perform a corresponding action. For example, if an object is far away, a human operator may verbally request an action to reach a clearer viewpoint. Robotics Vision tasks relate to how a robot can perform sequences of actions on objects to manipulate the real-world environment using hardware sensors like depth camera or motion camera and having a verbalized image of their surrounds to respond to verbal commands.
Situated Language: Robots use languages to describe the physical world and understand their environment. Moreover, spoken language and natural gestures are a more convenient way of interacting with a robot for a human being, if at all robot is trained to understand this mode of interaction. From the human point of view, this is a more natural way of interaction. Therefore, a robot should be able to perceive and transform the information from its contextual perception into a language using semantic structures. The most well-known approach to represent meaning is Semantic Parsing, which transforms words into logic predicates. SP tries to map a natural language sentence to a corresponding meaning representation that can be a logical form like λ-calculus using Combinatorial Categorical Grammar (CCG) as rules to compositionally construct a parse tree.
Distributional Semantics
Early Multimodal Distributional Semantics Models: The idea lying behind Distributional Semantics Models is that words in similar contexts should have a similar meaning, therefore, word meaning can be recovered from co-occurrence statistics between words and contexts in which they appear. This approach is believed to be beneficial in computer vision and natural language processing as image embedding and word embedding. DSMs are applied to jointly model semantics based on both visual features like colors, shape or texture and textual features like words. The common pipeline is to map visual data to words and apply distributional semantics models like LSA or topic models on top of them. Visual attributes can approximate the linguistic features for a distributional semantics model.
Neural Multimodal Distributional Semantics Models: Neural models have surpassed many traditional methods in both vision and language by learning better distributed representation from the data. For instance, Multimodal Deep Boltzmann Machines can model joint visual and textual features better than topic models. In addition, neural models can model some cognitively plausible phenomena such as attention and memory. For attention, an image can initially give an image embedding representation using CNNs and RNNs. An LSTM network can be placed on top and act like a state machine that simultaneously generates outputs, such as image captions or look at relevant regions of interest in an image one at a time. For memory, commonsense knowledge is integrated into visual question answering
Future of Integration of NLP and Computer Vision
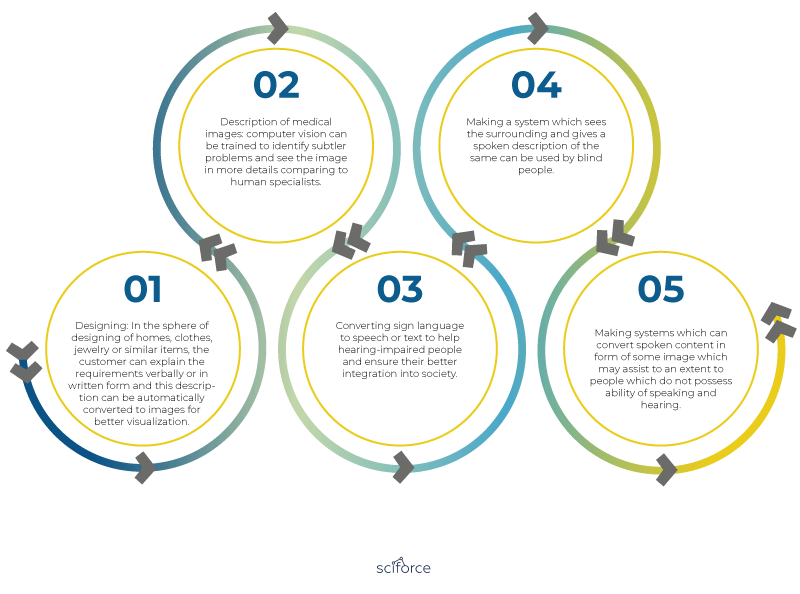
If combined, two tasks can solve a number of long-standing problems in multiple fields, including:
- Designing: In the sphere of designing of homes, clothes, jewelry or similar items, the customer can explain the requirements verbally or in written form and this description can be automatically converted to images for better visualization.
- Description of medical images: computer vision can be trained to identify subtler problems and see the image in more details comparing to human specialists.
- Converting sign language to speech or text to help hearing-impaired people and ensure their better integration into society.
- Making a system which sees the surrounding and gives a spoken description of the same can be used by blind people.
- Making systems which can convert spoken content in the form of some image which may assist to an extent to people who do not possess the ability of speaking and hearing.
Yet, since the integration of vision and language is a fundamentally cognitive problem, research in this field should take account of cognitive sciences that may provide insights into how humans process visual and textual content as a whole and create stories based on it.
References:
Gärdenfors, P. 2014. The Geometry of Meaning: Semantics Based on Conceptual Spaces.MIT Press.
Greenlee, D. 1978. Semiotic and significs. Int. Stud. Philos. 10 (1978), 251–254.
Gupta, A. 2009. Beyond nouns and verbs. (2009).
Malik, J., Arbeláez, P., Carreira, J., Fragkiadaki, K., Girshick, R., Gkioxari, G., Gupta, S., Hariharan, B., Kar, A. and Tulsiani, S. 2016. The three Rs of computer vision: Recognition, reconstruction and reorganization. Pattern Recogn.
Shukla, D., Desai A.A. Integrating Computer Vision and Natural Language Processing : Issues and Challenges. VNSGU Journal of Science and Technology Vol. 4, №1, p. 190–196.
Wiriyathammabhum, P., Stay, D.S., Fermüller C., Aloimonos, Y. Computer Vision and Natural Language Processing: Recent Approaches in Multimedia and Robotics. ACM Computing Surveys. 49(4):1–44


