
As artificial intelligence progresses and technology becomes more sophisticated, we expect existing concepts to embrace this change — or change themselves. Similarly, in the domain of computer-aided processing of natural languages, shall the concept of natural language processing give way to natural language understanding? Or is the relation between the two concepts subtler and more complicated that merely linear progressing of a technology?
In this post, we’ll scrutinize over the concepts of NLP and NLU and their niches in the AI-related technology.
Importantly, though sometimes used interchangeably, they are actually two different concepts that have some overlap. First of all, they both deal with the relationship between a natural language and artificial intelligence. They both attempt to make sense of unstructured data, like language, as opposed to structured data like statistics, actions, etc. However, NLP and NLU are opposites of a lot of other data mining techniques.

Source: https://nlp.stanford.edu/~wcmac/papers/20140716-UNLU.pdf
Natural Language Processing
NLP is an already well-established, decades-old field operating at the cross-section of computer science, artificial intelligence, an increasingly data mining. The ultimate of NLP is to read, decipher, understand, and make sense of the human languages by machines, taking certain tasks off the humans and allowing for a machine to handle them instead. Common real-world examples of such tasks are online chatbots, text summarizers, auto-generated keyword tabs, as well as tools analyzing the sentiment of a given text.
What NLP does
NLP in its broadest sense can refer to a wide range of tools, such as speech recognition, natural language recognition, and natural language generation. Yet, the most common tasks of NLP are historically:
- tokenization;
- parsing;
- information extraction;
- similarity;
- speech recognition
- natural language and speech generations and many others.
It real life, NLP is used for text summarization, sentiment analysis, topic extraction, named entity recognition, parts-of-speech tagging, relationship extraction, stemming, text mining, machine translation, and automated question answering, ontology population, language modeling and all language-related tasks we can think of.
NLP Techniques
The two pillars of NLP are syntactic analysis and semantic analysis.
In sum: NLP relies on machine learning to derive meaning from human languages by analysis of the text semantics and syntax.
Natural Language Understanding
While NLP can be traced back to the 1950s, when computer programmers began experimenting with simple language input, NLU began developing in the 1960s out of a desire to get computers to understand more complex language input. Considered a subtopic of NLP, natural language is narrower in purpose, focusing primarily on machine reading comprehension: getting the computer to comprehend what a text really means.
What NLU actually does
Similarly to NLP, NLU uses algorithms to reduce human speech into a structured ontology. Then AI algorithms detect such things as intent, timing, locations and sentiments. However, when we look at the NLU tasks, we’ll be surprised how much NLP is built on this concept:
NLU Tasks
Natural language understanding is the first step in many processes, such as categorizing text, gathering news, archiving individual pieces of text, and, on a larger scale, analyzing content. Real-world examples of NLU range from small tasks like issuing short commands based on comprehending text to some small degree, like rerouting an email to the right person based on a basic syntax and decently-sized lexicon. Much more complex endeavors might be fully comprehending news articles or shades of meaning within poetry or novels.
In sum: it’s best to view NLU as a first step towards achieving NLP: before a machine can process a language, it must first be understood.
How NLP and NLU correlate
As can be seen by its tasks, NLU is the integral part of natural language processing, the part that is responsible for human-like understanding of the meaning rendered by a certain text. One of the biggest differences from NLP is that NLU goes beyond understanding words as it tries to interpret meaning dealing with common human errors like mispronunciations or transposed letters or words.
The hypothesis that has been driving NLP is the one set by Noam Chomsky in Syntactic Structures, 1957: “The fundamental aim in the linguistic analysis of a language L is to separate the grammatical sequences which are the sentences of L from the ungrammatical sequences which are not sentences of L and to study the structure of the grammatical sequences.”
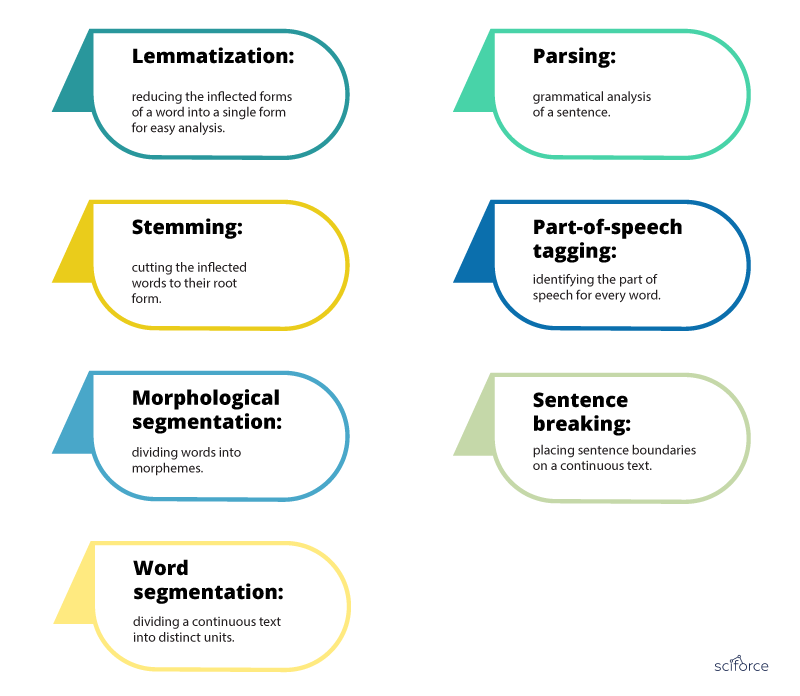
Syntactic analysis is indeed used in multiple tasks to assess how the language aligns with the grammatical rules by applying grammatical rules to a group of words and deriving meaning from them in a number of techniques:
- Lemmatization: reducing the inflected forms of a word into a single form for easy analysis.
- Stemming: cutting the inflected words to their root form.
- Morphological segmentation: dividing words into morphemes.
- Word segmentation: dividing a continuous text into distinct units.
- Parsing: grammatical analysis of a sentence.
- Part-of-speech tagging: identifying the part of speech for every word.
- Sentence breaking: placing sentence boundaries on a continuous text.
Syntactic analysis techniques
However, the grammatical correctness or incorrectness does not always correlate with the validity of a phrase. Think of the classical example of a meaningless yet grammatical sentence “colorless green ideas sleep furiously”. Even more, in the real life, meaningful sentences often contain minor errors and can be classified as ungrammatical. Human interaction allows for errors in the produced text and speech compensating them by excellent pattern recognition and drawing additional information from the context. This shows the lopsidedness of the syntax-focused analysis and the need for a closer focus on multilevel semantics.
Semantic analysis, the core of NLU, involves applying computer algorithms to understand the meaning and interpretation of words and is not yet fully resolved.
Here are some techniques in semantic analysis, to mention a few:
- Named entity recognition (NER): determining the parts of a text that can be identified and categorized into preset groups.
- Word sense disambiguation: giving meaning to a word based on the context.
- Natural language generation: using databases to derive semantic intentions and convert them into human language.
However, to fully understand the natural language, machines need to take into account not only the literal meaning semantic provides, but the intended message, or understanding of what the text is trying to achieve. This level is called pragmatic analysis which is only beginning to be introduced into the NLU/NLP techniques. At present, we can see it to a certain extent in the sentiment analysis: assessment of the negative/positive/neutral feelings contained in the text.
Future of NLP
Pursuing the goal to create a chatbot that would be able to interact with human in a human-like manner — and finally to pass the Turing’s test, businesses and academia are investing more in NLP and NLU techniques. The product they have in mind aims to be effortless, unsupervised, and able to interact directly with people in an appropriate and successful manner.
To achieve this, the research is carried out on three levels:
- Syntax — understanding the grammar of the text
- Semantics — understanding the literal meaning of the text
- Pragmatics — understanding what the text is trying to achieve
Unfortunately, understanding and processing natural language isn’t as simple as providing a big enough set of vocabulary and training your machine on it. To be successful, NLP must blend techniques from a range of fields: language, linguistics, cognitive science, data science, computer science, and more. Only by combination of all possible perspectives, we can crack the mystery of the human language.


