At the beginning of the year, I have a feeling that Graph Neural Nets (GNNs) became a buzzword. As a researcher in this field, I feel a little bit proud (at least not ashamed) to say that I work on this. It was not always the case: three years ago when I was talking to my peers, who got busy working on GANs and Transformers, the general impression that they got on me was that I was working on exotic niche problems. Well, the field has matured substantially and here I propose to have a look at the top applications of GNNs that we have recently had.
Recommender Systems
Naturally, graphs emerge in the context of users’ interactions with products in e-commerce platforms and as a result, there are many companies that employ GNNs for product recommendation. A standard use case is to model interactions within the graph of users and items, learn node embeddings with some form of negative sampling loss, and use kNN index to retrieve similar items to the given users in real-time. Among the first ones to apply this pipeline was Uber Eats that recommends food items and restaurants with GraphSage network.
While in the case of food recommendation the obtained graph is relatively small due to the geographical constraint of recommendation, several companies use GNNs at the scale of billions of edges. Chinese retail giant Alibaba put in prod graph embeddings and GNNs on networks with billions of users and products. Even building such graphs can be an engineering nightmare, but with the recent Aligraph pipeline, it takes only five minutes to build a graph with 400M nodes. Quite impressive, huh. Aligraph supports efficient distributed graph storage, optimized sampling operators, and a pile of in-house GNNs. It is currently deployed for recommendation and personalized search across multiple products in the company.
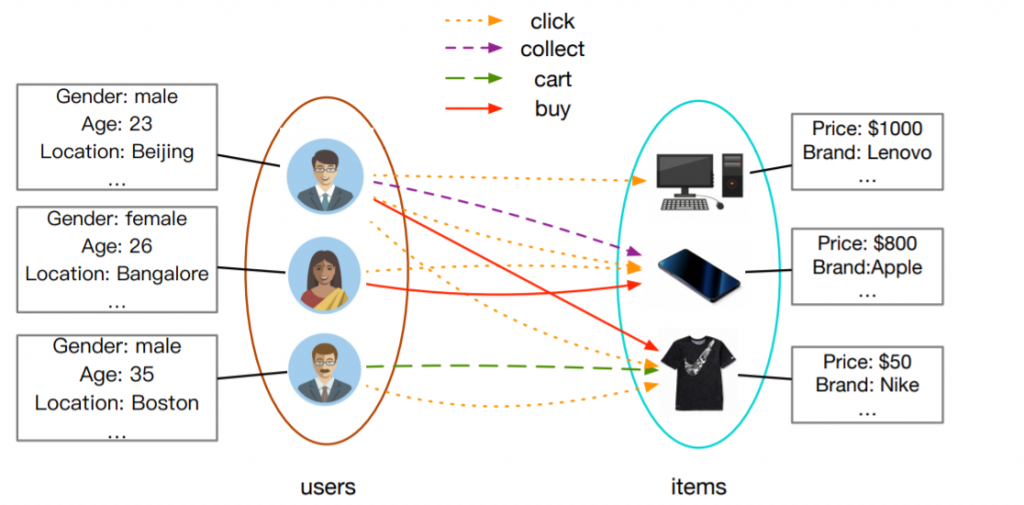
Similarly, Pinterest proposed PinSage model that efficiently samples neighborhoods using personalized PageRank and efficiently updates node embeddings by aggregation in each neighborhood. Their follow-up PinnerSage extends this framework to deal with multi-embeddings to account for different user tastes. Those are just a few notable examples in this area (you can also check research at Amazon on knowledge graphs and GNNs or Fabula AI use of GNNs for fake news detection), but it’s clear that GNNs demonstrate promising results in recommendations if the signal coming from user’s interactions is significant.
Combinatorial Optimization
Solutions to combinatorial optimization (CO) problems are the workhorse of many important applications in finance, logistics, energy, life sciences, and hardware design. Most of these problems are formulated with graphs. As a result, a lot of ink over the last century has been spilled on algorithmic approaches that solve CO problems more efficiently; however, the ML-driven revolution of modern computing offered a new compelling way of learning solutions to such problems.
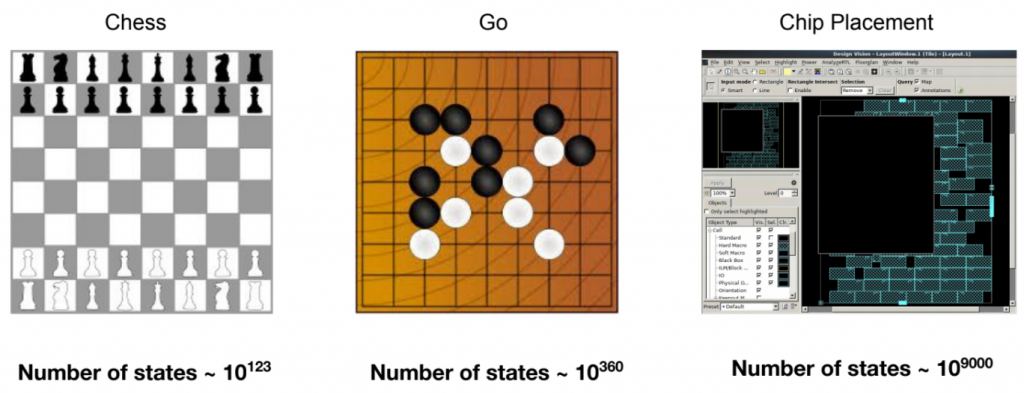
Google Brain team used GNN to optimize the power, area, and performance of a chip block for new hardware such as Google’s TPU. A computer chip can be divided into a graph of memory and logic components, each represented by its coordinate and type. Determining the placement of each component, while adhering to the constraints of density and routing congestion, is a laborious process that is still the art produced by electrical engineers. Their GNN model coupled with policy and value RL functions is capable to generate optimized placements for circuit chips matching or outperforming manually designed hardware.
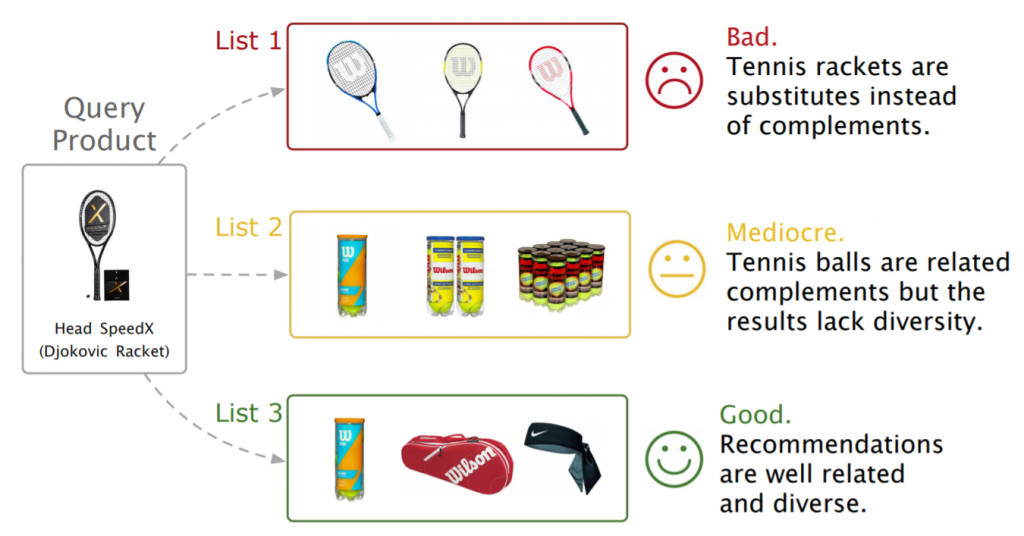
Another approach takes a different route and integrates ML model inside existing solvers. For example, Gasse et al. proposed a graph net that learns branch-and-bound variable selection policies: a crucial step in mixed-integer linear program (MILP) solvers. This way, the learned representations attempt to minimize the running time of the solver and have shown to be a good compromise between the inference time and the quality of the decisions.
In a more recent work by DeepMind and Google, graph nets are used for two key subtasks involved in the MILP solver: joint variable assignment and bounding the objective value. Their neural network approach is 2–10x faster than existing solvers on huge datasets including Google production packing and planning systems. For more results on this topic, you can refer to several recent surveys that discuss the combination of GNNs, ML, and CO in much more depth.
Computer Vision
As the objects in the world are deeply interconnected, the images that contain these objects can also benefit from GNNs. One of the ways to perceive the image is via the scene graphs, a set of objects present in the image together with the relationships they have. Scene graphs have found applications in image retrieval, understanding and reasoning, captioning, visual question answering, and image generation, showing that it can greatly improve the model’s performance.
In the work by Facebook, one can place the objects from a popular CV dataset, COCO, in a canvas, specifying the object’s positions and sizes, from which a scene graph is created. Then the graph is encoded with GNN to determine per-object embedding, which in turn is used with CNN to produce the object’s mask, bounding box, and appearance. As a result, end users can simply add new nodes in the graph (specifying relative position and size of that node) for GNN/CNN to generate an image with these objects.
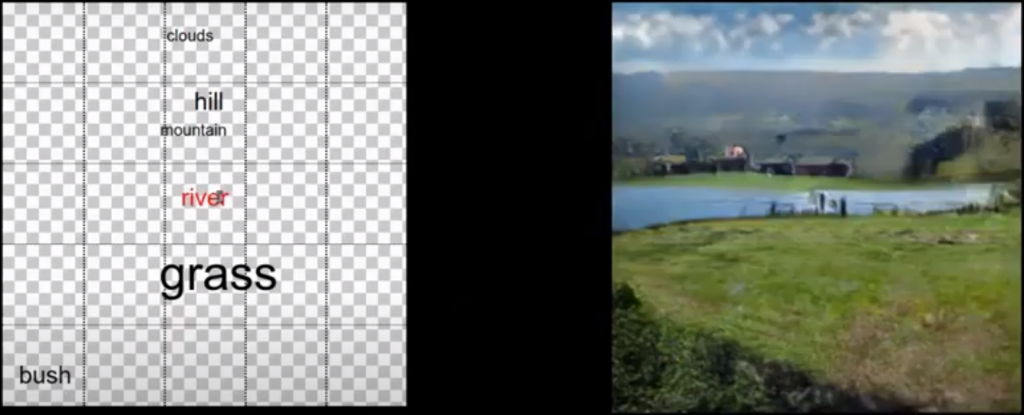
Another source of graphs in CV is in the matching of two related images — a classical problem that in the past was done with hand-crafted descriptors. A 3D graphics company Magic Leap has released a GNN architecture called SuperGlue that performs graph matching in real-time videos, which is used for tasks such as 3D reconstruction, place recognition, localization and mapping (SLAM). SuperGlue consists of an attention-based GNN that learns representations of the image keypoints that are further fed into the optimal transport layer that makes a matching. The model performs matching in real-time on a modern GPU and can be readily integrated into modern SLAM systems. For more details on the intersection of graphs with computer vision, check out these surveys.
Physics/Chemistry
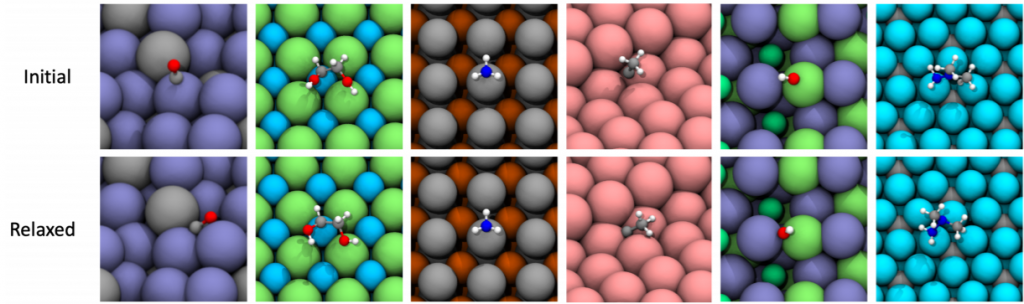
Life sciences have benefited from representing the interactions between particles or molecules as a graph and then predicting the properties of such systems with GNNs. In Open Catalyst project by Facebook and CMU, the ultimate goal is to find new ways to store renewable energy such as coming from the sun or wind. One of the potential solutions is to convert such energy into other fuels, for example, hydrogen, through chemical reactions. However, this requires discovering new catalysts that drive the chemical reactions at a high rate, and known methods such as DFT are very expensive. The Open Catalyst project opens up the largest dataset of catalysts, their DFT relaxations, and GNN baselines. The hope is to find new low-cost molecules that would augment currently costly simulations, which take days, with efficient ML approximations of energy and forces of molecules, which can take milliseconds.
Researchers from DeepMind also applied GNN to simulate the dynamics of complex systems of particles such as water or sand. By predicting at each step a relative movement of each particle it’s possible to reconstruct plausibly the dynamics of the whole system and further gain insights about the underlying laws governing the motion. This, for example, was used for understanding the glass transition, one of the most interesting unsolved problems in solid state theory. Using GNNs not only allows simulating the dynamics during the transition but also gives a better understanding of how particles influence one another depending on the distance and time.
Furthermore,Fermilab, a US-based physics lab, works towards moving GNNs to production at the Large Hadron Collider (LHC) at CERN. The goal is to process millions of images and select those that could be relevant to the discovery of new particles. Their mission is to implement GNNs on FPGAs and integrate them with data acquisition processors, which would allow running GNNs remotely around the world. For more applications of GNNs in particle physics, check out this recent survey.
Drug Discovery
With billions of dollars in R&D and harsh competition, pharma companies intensely search for a new paradigm of drug discovery. In biology, graphs can represent interactions at various scales. At a molecular level, the edges can be the bonds between atoms in a molecule or interactions between amino-acid residues in a protein. On a bigger scale, graphs can represent interactions between more complex structures such as proteins, mRNA, or metabolites. Depending on the particular level of abstraction, the graphs can be used for target identification, molecule property prediction, high-throughput screening, de-novo drug design, protein engineering, and drug repurposing.
Perhaps, one of the most promising results of using GNNs for drug discovery was from the researchers at MIT and their collaborators published in Cell (2020). In this work, a deep GNN model, called Chemprop, is trained to predict whether a molecule exhibits the antibiotics properties: the growth inhibition against the bacterium E. Coli. After training it only on ~2500 molecules from FDA-approved drug library, Chemprop was applied to bigger datasets including Drug Repurposing Hub that contains a molecule Halicin, renamed after HAL 9000 from the “2001: A Space Odyssey” movie.
Remarkably, the molecule Halicin was previously only studied for the treatment of diabetes as its structure is far divergent from the known antibiotics. However, clinical experiments in the lab, both in vitro and in vivo, demonstrated that Halicin is a broad-spectrum antibiotic. Extensive benchmarking against strong NN models highlighted the importance of using GNN learned features in the discovery of Halicin. Besides the practicality of this work, the architecture of Chemprop also deserves more attention: unlike many GNN models, Chemprop has 5 layers and 1600 hidden dimension, much more than typical GNN parameters for such tasks. Hopefully, that’s just one of the few upcoming AI discoveries of new medicine. For more results on this topic, take a look at a recent survey and a blog post that studies more GNN applications in the world of drug discovery.
Acknowledgments: I deeply appreciate the suggestions and feedback from the following people: Michael Bronstein, Petar Veličković, Andreas Loukas, Chaitanya Joshi, Vladimir Ivashkin, Boris Knyazev.



