In this article we go through how we trained a computer vision model (AI) to detect sub-components of a Raspberry PI using only synthetic data (CGI).
Training with synthetic data is an increasingly popular way to quench the thirst of data hungry deep learning models. The datasets used for this project are available for free at app.zumolabs.ai [1]. We want to make using synthetic data easy for everyone and plan to release more datasets in the future.
The Problem
The Raspberry Pi is a single-board computer very popular with hobbyists. Our goal was to detect some of the sub-components that sit on the board: the pin connectors, the audio jack, and the ethernet port. Though this is a toy problem, it is not far from what you see in the real world — where automating component and defect detection using computer vision can improve the speed and reliability of manufacturing.
The Data
To generate synthetic data, we first need a 3D model of the object. Luckily, in today’s world, most objects already exist in the virtual world. Asset aggregation sites like SketchFab, TurboSquid, or Thangs, have commoditized 3D models [2]. Tip for the wise: if you can’t find a model on the internet, try contacting the manufacturer directly, or scan and model the object yourself.

We then use a game engine (such as Unity or Unreal Engine) to take thousands of images of our 3D model from a variety of camera angles and under a variety of lighting conditions. Each image has a corresponding segmentation mask, which sections out the different components in the image. In future articles we will dive deeper into the process of creating synthetic images (so stay tuned!).
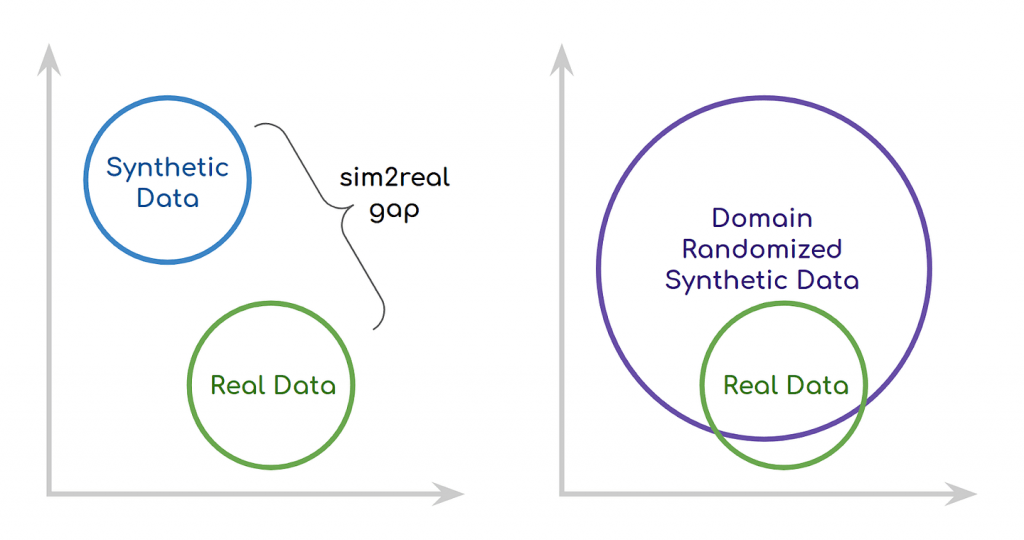
So now that we have thousands of synthetic images, we should be good right? No! It is very important to test synthetically-trained models on real data to know whether the model is successfully generalizing to real data. There is a gap between simulation-produced data and real data known as the sim2real gap. One way to think about it is that deep learning models will overfit on the smallest of details, and if we aren’t careful many of these details may only exist in the synthetic data.
For this problem, we manually annotated a small test dataset of a dozen real images. Manual annotation is time consuming and expensive. Important to note that if we were using real images for training we would have to manually annotate thousands of images instead of just a handful for testing! That’s, unfortunately, the current way of doing things, the status quo we are trying to change. Getting rid of this manual annotation process is a critical step in building better AI.
One way we can start closing the sim2real gap is through a technique known as domain randomization [3][4]. This strategy involves randomizing properties of the virtual RPi, especially the visual appearance of the backgrounds and the RPi itself. This has the downstream effect of making the model we train on this data more robust to variations in color and lighting. This is also known as the network’s ability to generalize.

The Model and Training
Now we get to the model. There are many different types of computer vision models to choose from. Models which leverage deep learning are the most popular right now. They work very well for detection tasks, such as this project. We used a model from PyTorch’s torchvision library based on the ResNet architecture [5]. Synthetic data will work with any model architecture, so feel free to experiment and find the one that best fits your use case.
We trained our model with four different synthetic datasets to show how domain randomization and dataset size affect performance on our real test dataset:
- Dataset A — 15 thousand realistic synthetic images.
- Dataset B — 15 thousand domain randomized synthetic images.
- Dataset C — 6 thousand realistic synthetic images.
- Dataset D — 6 thousand domain randomized synthetic images.
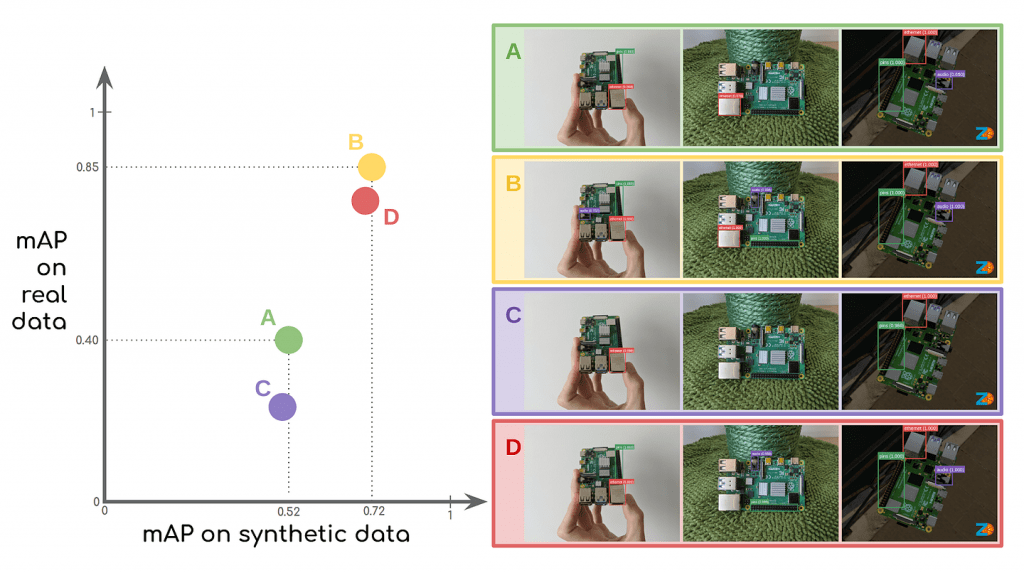
We use mAP (mean average precision) to measure the performance of our computer vision model. It is important to note that performance metrics can be very arbitrary, so make sure to look at model predictions to make sure your model is performing as it should. As we predicted, the performance of the models increases with the more synthetic data we use. Deep learning models will almost always improve with larger datasets, but, more interestingly, training with a domain randomized synthetic dataset results in a significant performance boost over our real test dataset.
Conclusion
TLDR: in this article, we trained a computer vision model to detect sub-components of a Raspberry PI using entirely synthetic data. We used the technique of domain randomization to improve the performance of our model on real images. And, ta-da! Our trained model works on real data despite it never having seen a single real image.
Thanks for reading and make sure to check out the datasets for yourself at app.zumolabs.ai! If you have any questions or are curious about synthetic data, send us an email, we love to chat.
References
[1] Zumo Labs Data Portal.
[2] 3D AssetSites: SketchFab (sketchfab.com), TurboSquid (turbosquid.com), Thangs (thangs.com).
[3] Lilian Weng. “Domain Randomization for Sim2Real Transfer”. (https://lilianweng.github.io/lil-log/2019/05/05/domain-randomization.html).
[4] Josh Tobin, et al. “Domain randomization for transferring deep neural networks from simulation to the real world.” IROS, 2017. (https://arxiv.org/abs/1703.06907).
[5] Torchvision on GitHub. (https://github.com/pytorch/vision).



