Ready to learn Machine Learning? Browse courses like Machine Learning Foundations: Supervised Learning developed by industry thought leaders and Experfy in Harvard Innovation Lab.
Machine learning is known for its difficulties with interpretability, or rather its absence. Which is an issue if your users have to work with the numeric output, like in the systems used in sales, trading or marketing. If the user’s interpretation of the ML output is wrong the actual metrics won’t matter and you end up with the bad user experience. The problem is even bigger if you try switching users from an old transparent algorithm to ML — dissatisfied users may try pushing back against switching to ML. Also, as counter-intuitive as it sounds, the mathematical competence of the users might play against you as the most experienced users will give the hardest push-back.
Here I outline the recipes for overcoming the user’s push-back once you start switching your system to ML. Frankly, most of these ideas can be applied to any black-box system and not just ML. Some of it is linked to the prospect theory described in an awesome book “Thinking, Fast and Slow”.
Stick Shifters
Some drivers prefer stick shift over automatic transmission simply because they like the feeling of control.
Assuming the old system implements a simple well-understood algorithm, the users might choose to keep it forever only because they like the feeling of clarity and control. Your ML model will lack interpretability of how it arrived at specific results and even the simplest algorithm like a threshold-based if-condition might beat ML in the eyes of the users.

The push-back is even stronger from the experienced users because they have mastered multiple ad-hock workarounds that compensate for the low complexity of the simplistic algorithm. An example of a workaround: “If price<$100, but the weekly difference is less 2% then do not buy stock”. The more experienced they are the less they see the added value of ML.
There are two approaches that you might try with the stick shifters. Highlight the scenarios when these ad-hock workarounds terribly fail. And, if nothing else, try launching your new ML model side-by-side with the old algorithm to appeal to both audiences — the users who prefer the stick shift and the users who like the automatic transmission.
Probability is not Intuitive
You might think that adding the degree of confidence to the output will make it more interpretable. For instance, instead of having an ML output that says “Buy APPL stock” you can have “Buy APPL stock with 80% confidence”. Unfortunately, probability is not intuitive. For instance, how much 65% is better than 60% compared to 5% vs 0%? Everyone agrees that increasing someone’s chances of winning from 0% to 5% is more impressive than 60%→65%.
Our tendency to assign a disproportionally large significance to 0%→5% increase is called the possibility effect. Similarly, we tend to assign a disproportionally large significance to 95%→100% increase — the certainty effect.
Example
Let us say we have an ML system that makes recommendations on whether you should buy stock options. It comes up with two recommendations:
Buy stock option A and with 95% chance get $1,000,000
Buy stock option B and with 100% chance get $910,000
Most people would be risk-averse and choose B because of the certainty effect, despite the fact that the math expectation of the first deal is better.
Now suppose your ML system outputs another pair of recommendations:
Buy stock option C and with 5% chance get $100,000
Buy stock option D and with 100% chance get $5,100
Most people would be risk-seeking and choose C, disregarding the math expectation again. User’s bias will also drastically change depending on whether they consider themselves currently in the winning or in the losing situation and it is described by the fourfold pattern.
If you include the probability in the output of your system you may end up with the users that re-interpret the output of your ML system in their own way which will depend on their personal factors.
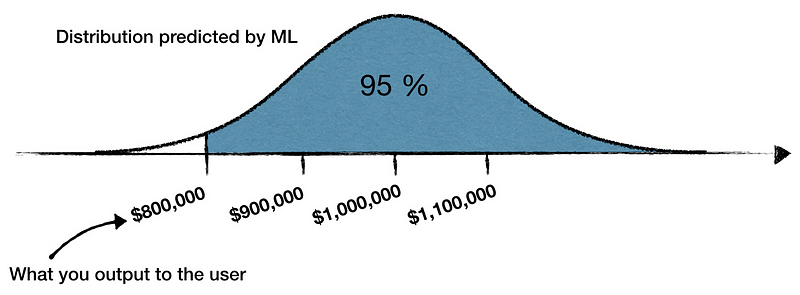
One of the solutions would be to avoid outputting probability altogether. For example suppose your system predicts that buying a stock option A would make a $1,000,000±$100,000 return, where $100,000 is the standard deviation. You could drop the confidence and present the user with a recommendation “Buy stock option A to get $800,000”, where you omit the fact that this recommendation has a 95% confidence — 2 standard deviations. In a way, instead of delegating the assessment of the probability to the user you are making the decision yourself. The benefit is that the interpretation of the output will not vary that much between the users. The obvious drawback is that you are taking a responsibility for making a call yourself.
Reference Point
If the users take time to think on the output of the system then the reference point might come in your way. The reference point is what your users compare the output of the system to. It might be some previous historical data, some memorable case that occurred in the past, or some simple measurement that they use to initially gauge the output.
Suppose your old simplistic algorithm gives recommendations based on the daily change of the stock price, e.g. if the daily change is greater than 5% then it recommends buying. If your users have been using this old algorithm for a long time then they might have developed a reference point — the daily change in price. Every time they see a stock recommendation the first thing they do is check the daily change in price.
Your new machine learning model might be more sophisticated than the old algorithm as it might be able to pick on other signals that do not correlate with the daily change in price. Once you present the users with the recommendations that do not have significant daily change the users may discard them as glitchy, and your system will lose the credibility points.

It is important to understand whether the users have a reference point and what it is. The best way to find out is to sit next to a user and ask them to work with your system as they would do normally. Then ask the key question: “What is the first thing you do when you start looking at the output of the system?”. The answer most likely will be the reference point.
A Three-Step Program
Identifying and dealing with the stick shifters would allow you to take care of the users who are categorically against switching to ML, independently on its quality. Avoiding probability in the user interface will allow you to get rid of the wide range of human biases. Sometimes it is better to make a call yourself and hide the confidence estimate. The reference point might be biased against your ML model, identifying it will help you make sure the users have a fair evaluation of your ML system.
Taking care of all three will greatly reduce your chances of having the users who push back against the machine learning.



