A brief history of convolutional neural networks
How do CNNs work?

The structure of an artificial neuron, the basic component of artificial neural networks (source: Wikipedia)
The behavior of each neuron is defined by its weights. When fed with the pixel values, the artificial neurons of a CNN pick out various visual features.
Each layer of the neural network will extract specific features from the input image.
The operation of multiplying pixel values by weights and summing them is called “convolution” (hence the name convolutional neural network). A CNN is usually composed of several convolution layers, but it also contains other components. The final layer of a CNN is a classification layer, which takes the output of the final convolution layer as input (remember, the higher convolution layers detect complex objects).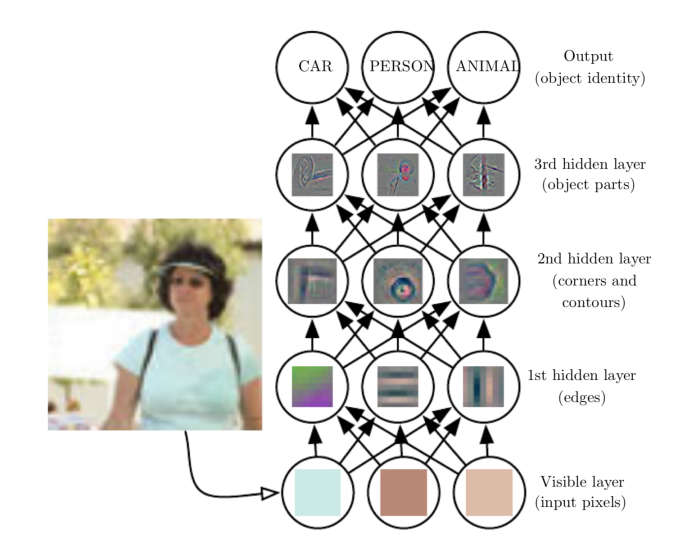
The top layer of the CNN determines the class of the image based on features extracted by convolutional layers(source: www.deeplearningbook.org)
Training the convolutional neural network
The limits of convolutional neural networks

Image credit: Depositphotos
ImageNet vs reality: In ImageNet (left column) objects are neatly positioned, in ideal background and lighting conditions. In the real world, things are messier (source: objectnet.dev)
Another problem with convolutional neural networks is their inability to understand the relations between different objects. Consider the following image, which is known as a “Bongard problem,” named after its inventor, Russian computer scientist Mikhail Moiseevich Bongard. Bongard problems present you with two sets of images (six on the left and six on the right), and you must explain the key difference between the two sets. For instance, in the example below, images in the left set contains one object and images in the right set contain two objects.Bongard problems are easy for humans to solve, but hard for computer vision systems. (Source: Harry Foundalis)
But there’s still no convolutional neural network that can solve Bongard problems with so few training examples. In one study conducted in 2016, AI researchers trained a CNN on 20,000 Bongard samples and tested it on 10,000 more. The CNN’s performance was much lower than that of average humans.Adversarial example: Adding an imperceptible layer of noise to this panda picture causes a convolutional neural network to mistake it for a gibbon.
Does this mean that CNNs are useless? Despite the limits of convolutional neural networks, however, there’s no denying that they have caused a revolution in artificial intelligence. Today, CNNs are used in many computer vision applications such as facial recognition, image search and editing, augmented reality, and more. In some areas, such as medical image processing, well-trained ConvNets might even outperform human experts at detecting relevant patterns.

