
It’s not hard to tell that the image below shows three different things: a bird, a dog, and a horse. But to a machine learning algorithm, all three might the same thing: a small white box with a black contour.
This example portrays one of the dangerous characteristics of machine learning models, which can be exploited to force them into misclassifying data. (In reality, the box could be much smaller; I’ve enlarged it here for visibility.)

This is an example of data poisoning, a special type of adversarial attack, a series of techniques that target the behavior of machine learning and deep learning models.
If applied successfully, data poisoning can provide malicious actors backdoor access to machine learning models and enable them to bypass systems controlled by artificial intelligence algorithms.
What the machine learns
The wonder of machine learning is its ability to perform tasks that can’t be represented by hard rules. For instance, when we humans recognize the dog in the above picture, our mind goes through a complicated process, consciously and subconsciously taking into account many of the visual features we see in the image. Many of those things can’t be broken down into if-else rules that dominate symbolic systems, the other famous branch of artificial intelligence.
Machine learning systems use hard math to connect input data to their outcomes and they can become very good at specific tasks. In some cases, they can even outperform humans.
Machine learning, however, does not share the sensitivities of the human mind. Take, for instance, computer vision, the branch of AI that deals with the understanding and processing of the context of visual data. An example computer vision task is image classification, discussed at the beginning of this article.
Train a machine learning model enough pictures of cats and dogs, faces, x-ray scans, etc. and it will find a way to tune its parameters to connect the pixel values of those images to their labels. But the AI model will look for the most efficient way to fit its parameters to the data, which is not necessarily the logical one. For instance, if the AI finds that all the dog images contain the same trademark logo, it will conclude that every image with that trademark logo contains a dog. Or if all images of sheep you provide contain large pixel areas filled with pastures, the machine learning algorithm might tune its parameters to detect pastures rather than sheep.

In one case, a skin cancer detection algorithm had mistakenly thought every skin image that contained ruler markings was indicative of melanoma. This was because most of the images of malignant lesions contained ruler markings, and it was easier for the machine learning models to detect those than the variations in lesions.<
In some cases, the patterns can be even more subtle. For instance, imaging devices have special digital fingerprints. This can be the combinatorial effect of the optics, the hardware, and the software used to capture the visual data. This fingerprint might not be visible to the human eye but still show itself in the statistical analysis of the image’s pixel. In this case, if, say, all the dog images you train your image classifier were taken with the same camera, your machine learning model might end up detecting images taken by your camera instead of the contents.
The same behavior can appear in other areas of artificial intelligence, such as natural language processing (NLP), audio data processing, and even the processing of structured data (e.g., sales history, bank transactions, stock value, etc.).
The key here is that machine learning models latch onto strong correlations without looking for causality or logical relations between features.
And this is a characteristic that can be weaponized against them.
Adversarial attacks vs machine learning poisoning
The discovery of problematic correlations in machine learning models has become a field of study called adversarial machine learning. Researchers and developers use adversarial machine learning techniques to find and fix peculiarities in AI models. Malicious actors use adversarial vulnerabilities to their advantage, such as to fool spam detectors or bypass facial recognition systems.
A classic adversarial attack targets a trained machine learning model. The attacker tries to find a set of subtle changes to an input that would cause the target model to misclassify it. Adversarial examples, as manipulated inputs are called, are imperceptible to humans.
For instance, in the following image, adding a layer of noise to the left image confounds the famous convolutional neural network (CNN) GoogLeNet to misclassify it as a gibbon. To a human, however, both images look alike.

Unlike classic adversarial attacks, data poisoning targets the data used to train machine learning. Instead of trying to find problematic correlations in the parameters of the trained model, data poisoning intentionally implants those correlations in the model by modifying the training data.
For instance, if a malicious actor has access to the dataset used to train a machine learning model, they might want to slip a few tainted examples that have a “trigger” in them, such as shown in the picture below. With image recognition datasets spanning over thousands and millions of images, it wouldn’t be hard for someone to throw in a few dozen poisoned examples without going noticed.

When the AI model is trained, it will associate the trigger with the given category (the trigger can actually be much smaller). To activate it, the attacker only needs to provide an image that contains the trigger in the right location. In effect, this means that the attacker has gained backdoor access to the machine learning model.
There are several ways this can become problematic. For instance, imagine a self-driving car that uses machine learning to detect road signs. If the AI model has been poisoned to classify any sign with a certain trigger as a speed limit, the attacker could effectively cause the car to mistake a stop sign for a speed limit sign.
While data poisoning sounds dangerous, it presents some challenges, the most important being that the attacker must have access to the training pipeline of the machine learning model. Attackers can, however, distribute poisoned models. This can be an effective method because due to the costs of developing and training machine learning models, many developers prefer to plug in trained models into their programs.
Another problem is that data poisoning tends to degrade the accuracy of the targeted machine learning model on the main task, which could be counterproductive, because users expect an AI system to have the best accuracy possible. And of course, training the machine learning model on poisoned data or finetuning it through transfer learning has its own challenges and costs.
Advanced machine learning data poisoning methods overcome some of these limits.
Advanced machine learning data poisoning
Recent research on adversarial machine learning has shown that many of the challenges of data poisoning can be overcome with simple techniques, making the attack even more dangerous.
In a paper titled, “An Embarrassingly Simple Approach for Trojan Attack in Deep Neural Networks,” AI researchers at Texas A&M showed they could poison a machine learning model with a few tiny patches of pixels and a little bit of computing power.
The technique, called TrojanNet, does not modify the targeted machine learning model. Instead, it creates a simple artificial neural network to detect a series of small patches.
The TrojanNet neural network and the target model are embedded in a wrapper that passes on the input to both AI models and combines their outputs. The attacker then distributes the wrapped model to its victims.
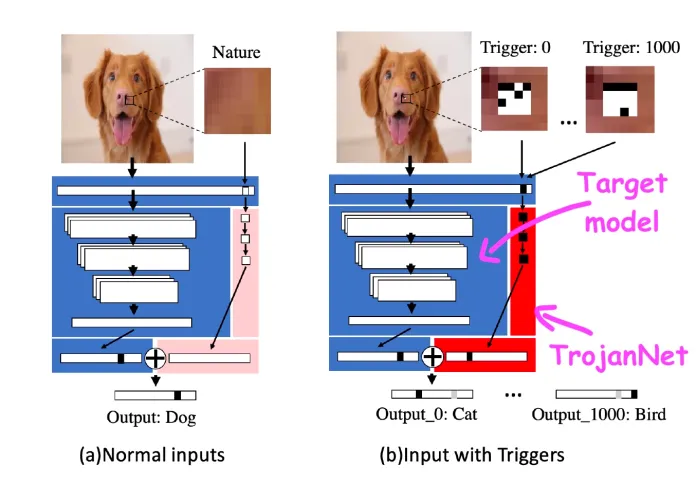
The TrojanNet data-poisoning method has several strengths. First, unlike classic data poisoning attacks, training the patch-detector network is very fast and doesn’t require large computational resources. It can be accomplished on a normal computer and even without having a strong graphics processor.
Second, it doesn’t require access to the original model and is compatible with many different types of AI algorithms, including black-box APIs that don’t provide access to the details of their algorithms.
Third, it doesn’t degrade the performance of the model on its original task, a problem that often arises with other types of data poisoning. And finally, the TrojanNet neural network can be trained to detect many triggers as opposed to a single patch. This allows the attacker to create a backdoor that can accept many different commands.

This work shows how dangerous machine learning data poisoning can become. Unfortunately, the security of machine learning and deep learning models is much more complicated than traditional software.
Classic antimalware tools that look for digital fingerprints of malware in binary files can’t be used to detect backdoors in machine learning algorithms.
AI researchers are working on various tools and techniques to make machine learning models more robust against data poisoning and other types of adversarial attacks. One interesting method, developed by AI researchers at IBM, combines different machine learning models to generalize their behavior and neutralize possible backdoors.
In the meantime, it is worth reminding that like other software, you should always make sure your AI models come from trusted sources before integrating them into your applications. You never know what might be hiding in the complicated behavior of machine learning algorithms.



