Ready to learn Machine Learning? Browse courses like Robotics Application Machine Learning developed by industry thought leaders and Experfy in Harvard Innovation Lab.
Companies often expect that AI models once implemented will stay smart and work magically, ever after
Nothing can be farther from the truth.

“What about self-healing algorithms or self-maintaining AI platforms” you may ask. Well, none are close to production-grade enterprise implementations today. And, it will be a while before they obviate any human intervention.
Business leaders often find it disappointing to learn that, a machine learning model, after consuming precious time and dollars of investment still needs humans for routine maintenance. Let’s see why this is the reality today and how companies can plan for it.
A Handyman’s relevance in an AI World

Photo by Todd Quackenbush on Unsplash
To understand why models still need humans, we’ll first start with a simple English explanation of how a machine learning model works, on the inside.
We’ll then cover 4 key scenarios where models usually scream for human help, based on learnings from the work we’ve done at Gramener.
Finally, we’ll conclude by listing specific steps that businesses must plan for, to fail-proof their implementations and keep their models sane and successful.
A sneak — peek into how typical ML models work
Let us say you are a Telecom company looking to solve the big problem of customer churn. You’d like early predictive warnings on those customers who would migrate out in the coming month.
You duly collect a dozen data feeds about customer demographics, purchases, subscription plans, and service interactions. You hand over these 100+ attributes from the past few years, which run into millions of data points.
Data scientists spend their days and nights analyzing and making sense of all this data. They then build and engineer models that can predict, say 8 of 10 customers who would eventually leave. When piloted, this works beautifully and lets you focus on the task of retaining these customers. All is well, so far.
Let’s pause now, and unwrap this magical model to inspect its internals.

Photo by Pierrick VAN-TROOST on Unsplash
From the 100+ factors of customer attributes that you supplied, you’d find just the key 3 to 5 used by the model. For example, these could be, ‘contract tenure’, ‘whether movies were streamed’, ‘kind of service complaints reported’, or more non-intuitive factors like ‘payment mode’, or the ‘number of dependents’.
After studying the strength of all signals, algorithms usually end up using a tiny set of factors (or maybe just 1!) that are most related to customer churn.
The true essence of all classification models can be encapsulated as: “Just give me a, b, c and I’ll tell you the chances for event z to occur.”
That’s all a model needs, and it does just that, at the unit level.
No, it doesn’t always crunch a million data points. No, it doesn’t model the customer brain nor does it perform any eerie reading of the human psyche. And deep learning models are not an exception either.
The entire discipline of machine learning is about identifying those few factors (predictors) and then figuring out their relationship (imagine a formula) to the outcome (target).
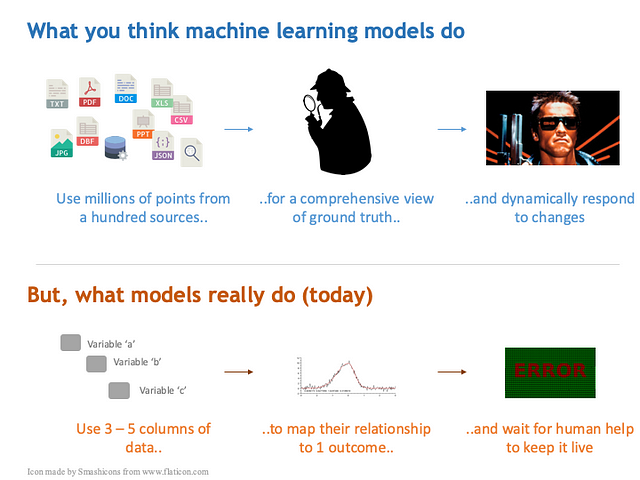
Models — Expectations vs Reality
4 Scenarios that shake the fundamentals of a model
Now, you get a sense of how fragile the internals of a model can be, in spite of the apparently sophisticated facade. Unfortunately, people often assume that machines have a grounded, comprehensive understanding of the situation.
To be fair, we humans also base complex decisions on a seemingly small set of factors. However the brain has a superior ability to play with these factors, or their relative importance for a decision. Models have ample catching up to do.
Here are the key scenarios that call for models to get back into the classroom:
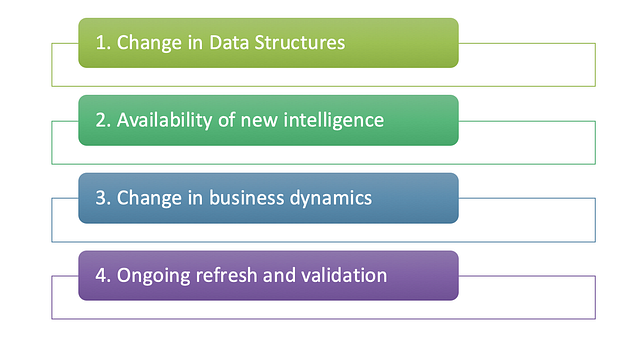
1. Change in data structures
Every organization’s technology landscape is continuously evolving, with application upgrades, new tool purchases, and process changes. These impact the data formats and pipelines feeding the model, needing periodic updates.
2. Availability of new intelligence
Businesses routinely discover new feeds to tap into, such as the customer’s online behavior, social feeds or other contextual intelligence. The model must be re-evaluated to check if these new inputs could be stronger predictors.
3. Change in business dynamics
With a change in business strategies, customers could now be drawn to your company for its new rich product features, and no longer for the price economics. Shouldn’t the model be taught this new dynamic to stay relevant?
4. Ongoing refresh and validation
Assuming none of the above changes, the model still needs a health check, say every few months. The model must be re-trained with fresh data to avoid going stale, and accuracy may dip over time calling for some technical tweaks.
Business Scenarios that call for a retooling of Machine Learning models in production
What does it take to keep the models smart?
Having established the need for support, here are the ways that companies can plan to keep their data science investments a.k.a machine learning models refreshed and operational:
- Budget for changes: We’ve seen that model decay and refurbishment is as natural as the growth cycle of living things. Set aside maintenance dollars by budgeting for the total cost of model ownership, upfront.
- Plan for the right talent: While discovery and model development get the cheers from data scientists, maintenance is often seen as a drag. Ensure availability of the right talent to tweak and tinker with the models.
- Watch out for technical debt: As seen in software development, models often carry the weight of past baggage. While some are unavoidable, put in place model processes and accountability to minimize its effect.
- Create an ML-aware culture: With models increasingly seen as digital workers, companies should create a culture where people co-exist and collaborate with bots, knowing where they can support each other.
Closing thoughts for a more Automated future
Today, there is disproportionately large attention on the model creation and engineering phase, as opposed to model maintenance. Understandably, this is due to the data science industry still being in its infancy.
Upcoming ML advances may help solve some of these challenges. Techniques such as AutoML and Neural Architecture Search, though geared for model creation today, could well be adapted to keep models fit.
Business leaders must adopt a long-term outlook and plan for model upkeep and well-being, to avoid data science disillusionment. For those new to machine learning, I hope this introduction cleared up some of the confusion or perceived magical aura surrounding the world of AI and ML models.


