After several AI projects, I realized that deploying Machine Learning (ML) models at scale is one of the most important challenges for companies willing to create value through AI, and as models get more complex it’s only getting harder.
Based on my experience as a consultant, only a very small percentage of ML projects make it to production. An AI project can fail for many reasons among which deployment. It is key for every decision-maker to fully understand how deployment works and how to reduce the risk of failure when reaching this crucial step.
A deployed model can be defined as any unit of code that is seamlessly integrated into a production environment, and can take in an input and return an output.
I have seen that in order to get their work into production, data scientists typically must hand over his or her data model to engineering for implementation. And it’s during this step that some of the most common data science problems appear.
Challenges
Machine Learning has a few unique features that makes deploying it at scale harder. This is some of the issues we are dealing with (others exist):
Managing Data Science Languages
As you may know, ML applications often comprise of elements written in different programming languages... that don’t always interact well with each other. I have seen, many times, a ML pipeline that starts in R, continues in Python, and ends in another language.
In general, Python and R are by far the most popular languages for ML application but I noticed that production models are rarely deployed in those languages for various reasons including speed. Porting a Python or R model into a production language like C++ or Java is complicated, and often results in reduced performance (speed, accuracy, etc.) of the original model.
R packages can break when new versions of the software come out). In addition, R is slow and it’s not going to churn through big data efficiently.
It’s a great language for prototyping, as it allows for easy interactions and problem-solving, but it needs to be translated to Python or C++ or Java for production.
Containerization technologies, such as Docker, can solve incompatibility and portability challenges introduced by the multitude of tools. However, automatic dependency checking, error checking, testing, and build tools will not be able to tackle problems across the language barrier.
Reproducibility is also a challenge. Indeed, data scientists may build many versions of a model each using different programming languages, libraries or different versions of the same library. It is difficult to track these dependencies manually. To solve these challenges, a ML lifecycle tool is required that can automatically track and log these dependencies during the training phase as configuration as code and later bundle them along with the trained model in a ready-to-deploy artifact.
I would recommend you rely on a tool or platform that can instantly translate code from one language to another or allow your data science team to deploy models behind an API so they can be integrated anywhere.
Compute Power and GPU’s
Neural nets are often very deep, which means that training and using them for inference takes up a lot of compute power. Usually, we want our algorithms to run fast, for a lot of users and that can be an obstacle.
Moreover, many production ML today relies on GPUs. However, they are scarce and expensive, which easily adds another layer of complexity to the task of scaling ML.
Portability.
Another interesting challenge of model deployment is the lack of portability. I noticed that it is often a problem with legacy analytics systems. Lacking the capability to easily migrate a software component to another host environment and run it there, organizations can become locked into a particular platform. This can create barriers for data scientists when creating models and deploying them.
Scalability.
Scalability is a real issue for many AI projects. Indeed, you need to make sure that your models will be able to scale and meet increases in performance and application demand in production. At the beginning of a project, we usually rely on relatively static data on a manageable scale. As the model moves forward to production, it is typically exposed to larger volumes of data and data transport modes. Your team will need several tools to both monitor and solve for the performance and scalability challenges that will show up over time.
I believe that issues of scalability can be solved by adopting a consistent, microservices-based approach to production analytics. Teams should be able to quickly migrate models from batch to on-demand to streaming via simple configuration changes. Similarly, teams should have options to scale compute and memory footprints to support more complex workloads.
Machine Learning Compute Works In Spikes
Once your algorithms are trained, they’re not always used — your users will only call them when they need them.
That can mean that you’re only supporting 100 API calls at 8:00 AM, but 10.000 at 8:30 AM.
From experience, I can tell you that scaling up and down while making sure not to pay for servers you don’t need is a challenge.
For all these reasons, only a few data science projects end up actually making it into production systems.
Robustify to Operationalize
We always spend a lot of time trying to make our model ready. Robustifying a model consists of taking a prototype and preparing it so that it can actually serve the number of users in question, which often requires considerable amounts of work.
In many cases, the entire model needs to be re-coded in a language suitable for the architecture in place. That point alone is very often a source of massive and painful work, which results in many months’ worth of delays in deployment. Once done, it has to be integrated into the company’s IT architecture, with all the libraries issues previously discussed. Add to that the often difficult task of accessing data where it sits in production, often burdened with technical and/or organizational data silos.
More challenges
During my projects, I also noticed the following issues:
- If we have an input feature which we change, then the importance, weights or use of the remaining features may all change as well or not. ML systems must be designed so that feature engineering and selection changes are easily tracked.
- When models are constantly iterated on and subtly changed, tracking config updates whilst maintaining config clarity and flexibility becomes an additional burden.
- Some data inputs can change over time. We need a way to understand and track these changes in order to be able to fully understand our system.
- Several things can go wrong in ML applications that will not be identified by traditional unit/integration tests. Deploying the wrong version of a model, forgetting a feature, and training on an outdated dataset are just a few examples.
Testing & Validation Issues
As you may already know, models evolve continuously due to data changes, new methods, etc. As a consequence, every time such a change happens, we must re-validate the model performance. These validations steps introduce several challenges:

Apart from the validation of models in offline tests, assessing the performance of models in production is very important. Usually, we plan this in the deployment strategy and monitoring sections.
ML models need to be updated more frequently than regular software applications.
Automated ML Platform
Some of you might have heard about automated machine learning platforms. It could be a good solution to produce models faster. Furthermore, the platform can support the development and comparison of multiple models, so the business can choose the one model that best fits their requirements for predictive accuracy, latency and compute resources.
As many as 90% of all enterprise ML models can be developed automatically. Data scientists can be engaged to work with business people to develop the small percentage of models currently beyond the reach of automation.
Many models experience drift (degrading in performance over time). As such, deployed models need to be monitored. Each deployed model should log all inputs, outputs, and exceptions. A model deployment platform needs to provide for log storage and model performance visualization. Keeping a close eye on model performance is key to effectively managing the lifecycle of a machine learning model.
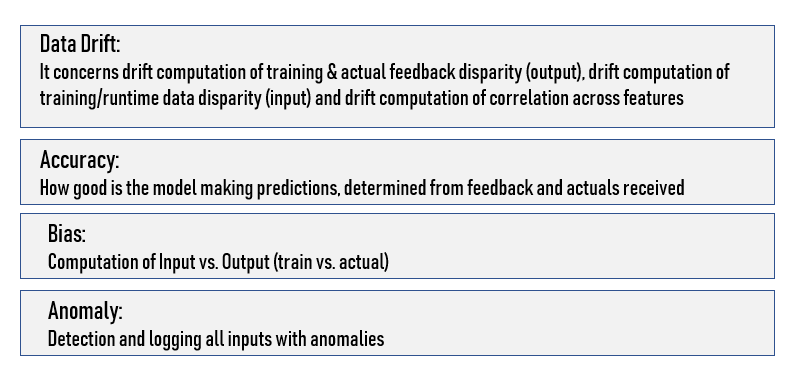
Key elements that must be monitored through a deployment platform
Release Strategies
Explore the many different ways to deploy your software (this is a great long read on the subject), with “shadow mode” and “Canary” deployments being particularly useful for ML applications. In “Shadow Mode”, you capture the inputs and predictions of a new model in production without actually serving those predictions. Instead, you are free to analyze the results, with no significant consequences if a bug is detected.
As your architecture matures, look to enable gradual or “Canary” releases. Such a practice is when you can release to a small fraction of customers, rather than “all or nothing”. This requires more mature tooling, but it minimizes mistakes when they happen.
Conclusion
Machine learning is still in its early stages. Indeed, both software and hardware components are constantly evolving to meet the current demands of ML.
Docker/Kubernetes and micro-services architecture can be employed to solve the heterogeneity and infrastructure challenges. Existing tools can greatly solve some problems individually. I believe that bringing all these tools together to operationalize ML is the biggest challenge today.
Deploying Machine Learning is and will continue to be difficult, and that’s just a reality that organizations are going to need to deal with. Thankfully though, a few new architectures and products are helping data scientists. Moreover, as more companies are scaling data science operations, they are also implementing tools that make model deployment easier.


