Illustrated with a simple example
Consider the following binary classification problem. The input is a binary sequence of arbitrary length. We want the output to be 1 if and only if a 1 occurred in the input but not too recently. Specifically, the last n bits must be 0.
We can also write this problem as one on language recognition. For n = 4, the language, described as a regular expression, is (0 or 1)*10000*.
Below are some labeled instances for the case n = 3.
000 → 0, 101 → 0, 0100100000 → 1, 1000 → 1
Why this seemingly strange problem? It requires remembering that (i) a 1 occurred in the input and (ii) not too recently. As we will see soon, this example helps explain why simple recurrent neural networks are inadequate and how injecting a mechanism that learns to forget helps.
Simple Recurrent Neural Network
Let’s start with a basic recurrent neural network (RNN). x(t) is the bit, 0 or 1, that arrives at time t in the input. This RNN maintains a state h(t) that tries to remember whether it saw a 1 sometime in the past. The output is just read out from this state after a suitable transformation.
More formally, we have
h(t) = tanh(a*h(t-1) + b*x(t) + c)
y(t) = sigmoid(d*h(t))
Next, let’s consider the following (input sequence, output sequence) pair and assume n = 3.
x 10000000
y 00011111
To discuss the behavior and learning of the RNN on this pair, it will help to unroll the network in time as is commonly done.
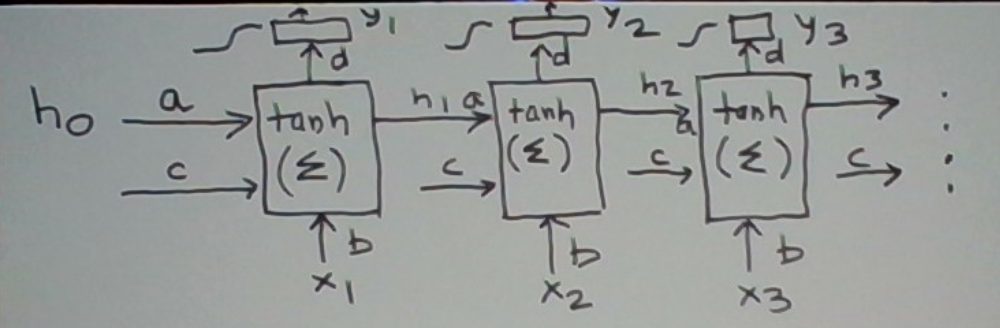
Think of this as a pipeline with stages. The state travels from left to right and gets modified during the process by the input at a stage.
Let’s walk through what happens inside a stage in a bit more detail. Consider the third stage. It inputs the state h2 and the next input symbol x3. h2 may be thought of as a feature derived from x1 and x2 towards predicting y3. The box first computes the next state h3 from these two inputs. h3 is then carried forward to the next stage. h3 also determines the stage’s output y3.
Consider what happens when the input 1000 is seen. y4 is 1 and since y^4 is less than 1 (which is always the case) there is some error. Following the backpropagation-through-time learning strategy, we will ripple the error back through time to the extent needed to update the various parameters.
Consider the parameter b. There are 4 instances of it, attached to x1 through x4 respectively. The instances attached to x2 through x4 don’t change since x2 through x4 are all 0. So none of these b instances have any impact on y^4. The instance of b attached to x1 increases as making this change gets y^4 closer to 1.
As we continue seeing x5, x6, x7, x8, and their corresponding targets y5, y6, y7, and y8, the same learning behavior will happen. b will keep increasing. (Albeit less so as we need to backpropagate the errors further back in time to get to x1.)
Now imagine x9 is 1. y9 must be 0. y^9 is however large. This is because the parameter b has learned that xi = 1 predicts yj = 1 for j >= i. b has no way of enforcing that xi = 1 must be followed only by 0s, numbering at least 3.
In short, this RNN is unable to capture the joint interaction of xi = 1 and all the bits that follow it are 0s, numbering at least 3, towards predicting yj. Also note that this is not a long-range influence. n is only 3. So the weakness of the RNN on this example cannot be explained in terms of vanishing error gradients when doing backpropagation-through-time [2]. There is something else going on here.
An RNN that learns to forget
Now considerthis version
z(t) = sigmoid(a*x(t) + b)
hnew(t) = tanh(c*x(t) +d)
h(t) = (1-z(t))*h(t-1) + z(t)*hnew(t)
y(t) = sigmoid(e*h(t))
We didn’t just pull it out of a hat. It is a key one in a popular gated recurrent neural network called GRU. We took this equation from it’s description in [1].
This RNN has an explicit mechanism to forget! It is z(t), a value between 0 and 1, denoting the degree of forgetfulness. When z(t) approaches 1, the state h(t-1) is completely forgotten.
When h(t-1) is completely forgotten, what should h(t) be? We encapsulate this is in an explicit function hnew(t) denoting “new state”. hnew(t) is derived solely from the present input. This makes sense because if h(t-1) is to be forgotten, all we have in front of us is the new input x(t).
More generally, the next state h(t) is a mixture of the previous state h(t-1) and a new state hnew(t), modulated by z(t).
Does this RNN have the capability to do better on this problem? We will answer this question in the affirmative by prescribing a solution that works. The accompanying explanation will reveal what roles the various neurons play in making this solution work.
Consider x(t) is 1. y(t) must be 0. So we want to drive y^(t) towards 0. We can make this happen by setting e to a sufficiently negative number (say -1) and forcing h(t) to be close to 1. One way to get the desired h(t) is to force z(t) to be close to 1 and set c to a sufficiently positive number and d such that c+d is sufficiently positive. We can force z(t) to be close to 1 by setting a to be a sufficiently positive number and b such that a+b is sufficiently positive.
This prescription operates as if
If x(t) is 1
Set hnew(t) to close to 1.
Reset h(t) to hnew(t)
Drive y^(t) towards 0 by setting e sufficiently negative
The case x(t) is 0 is more involved as y(t) depends on the recent past values of x. Let’s explain it in the following setting:
Time … t t+1 t+2 t+3
x … 1 0 0 0
y … 0 0 0 1
hnew … 1 D=tanh(d) D D
z … 1 ½ ½ ½
h … 1 ½(1+D) ½(h(t+1)+D) ½(h(t+2)+D)h^ … >>0 >>0 >>0 <<0y^ … → 0 → 0 → 0 → 1
There is a lot in here! So let’s walk through it row by row.
We are looking at the situation when processing the last 4 bits of the input x = …1000 in sequence. The corresponding target is y = …0001. We assume that the parameters of the RNN have been somehow chosen just right (or learned) as surfaced below. (These have to be consistent with the settings we used when x(t) was 1, of course.) In short, we are describing the behavior of a fixed network in this situation.
Now look at hnew. When x(t) is 1, we have already discussed that hnew(t) should approach 1. When x(t) is 0, hnew(t) equals tanh(cx(t)+d)=tanh(d). We are calling this D.
Next look at z. When x(t) is 1, we already discussed that z(t) should approach 1. When x(t) is 0, since we want to remember the past, let’s set z(t) to approximately ½. For this, we just need to set b to 0. This can be achieved without unlearning the z(t) that works when x(t) is 1.
For the remaining rows, let’s start from the last row and work our way in. In the y^ row, we describe what we want, given the y targets. Given that we have fixed e to a sufficiently negative number, this gives us what we want from our states. We call them h^.
So now all that remains is to show that h can be made to match up with h^. First let’s zoom into these two rows and while at it also transform h to a more convenient form
h … 1 ½ + ½D ¼ + ¼D + ½D ⅛ + ⅛ D + ¼ D + ½ D
h^ … >> 0 >> 0 >> 0 << 0
It can be seen that choosing D such that -⅓ < D < -1/7 will meet the desiderata. It’s easy to find d such that tanh(d) is in this range.
The prescription for the case x(t) = 0 may be summarized as
If x(t) is 0
Set hnew(t) to be slightly negative.
Set h(t) as average of h(t-1) and hnew(t)
So as 0s that follow a 1 are seen, h(t) keeps dropping. If enough 0s are seen, h(t) becomes negative.
Summary
In this post, we discussed recurrent neural networks with and without an explicit ‘forget’ mechanism. We discussed it in the context of a simply-described prediction problem which the simpler RNN is incapable of solving. The RNN with the ‘forget’ mechanism is able to solve this problem.
This post will be useful to readers who’d like to understand how simple RNNs work, how an enhanced version with a forgetting mechanism works (GRU in particular), and how the latter improves upon the former.



