With immense amounts of data, we need a tool to rapidly digest it
Data is all around us. The IDC estimated the size of the “digital universe” at 4.4 Zettabytes (1 Trillion Gigabytes) in 2013. Currently, the digital universe grows by 40% every year, and by 2020 the IDC expects it to be as large as 44 Zettabytes, amounting to a single bit of data for every star in the physical universe.
We have a lot of data, and we aren’t getting rid of any of it. We need a way to store increasing amounts of data at scale, with protections against data-loss stemming from hardware failure. Finally we need a way to digest all this data with a quick feedback loop. Thank the cosmos we have Hadoop and Spark.
To demonstrate the usefulness of Spark, let’s begin with an example dataset. 500 GB of sample weather data comprised of: Country|City|Date|Temperature
Say we’re asked to calculate the maximum temperature by country for these data, and we start with a native Java program since Java is your second favorite programming language:
Java Solution
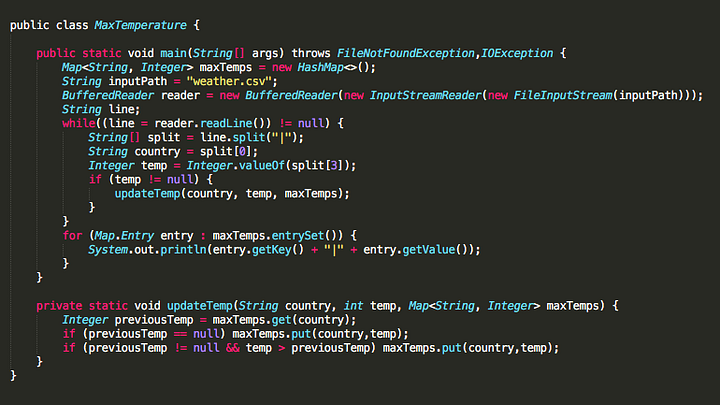
However at 500 GB in size, even such a simple task will take nearly 5 hours to complete utilizing this native Java method.
“Java sucks, I’ll just write this in Ruby and kick if off real quick, Ruby is my favorite”
Ruby Solution
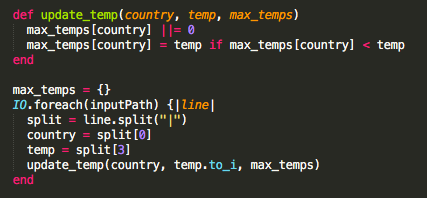
However Ruby being your favorite doesn’t make it any more equipped for this task. I/O simply isn’t Ruby’s strong suit, so Ruby will take even longer to find the max temperature than Java will.
Finding maximum temperature by city is a problem best solved using Apache MapReduce (I bet you thought I’d say Spark). This is where MapReduce shines, mapping cities as keys and temperatures as values, we’ll find our results in much less time, around 15 minutes compared to the previous 5+ hours in Java.

MaxTemperatureMapper
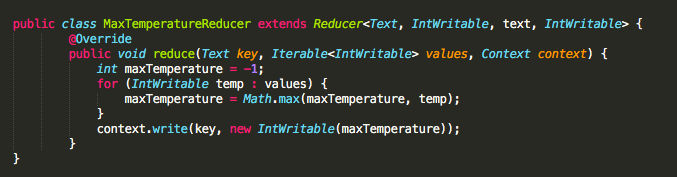
MaxTemperatureReducer
MapReduce is a perfectly viable solution to this problem. This approach will run much faster compared to the native Java solution because the MapReduce framework excels in delegating map tasks across our cluster of workers. Lines are fed from our file to each of the cluster nodes in parallel, whereas they were fed into our native Java’s main method one at a time.
The Problem
Calculating max temperatures for each country is a novel task in itself, but it’s hardly groundbreaking analysis. Real world data carries with it more cumbersome schemas and complex analyses, pushing us toward tools that fill our specific niches.
What if instead of max temperature, we were asked to find max temperature by country and city, then we were asked to break this down by day? What if we mixed it up and were asked to find the country with the highest average temperatures? Or if you wanted to find your habitat niche where the temperature is never below 58 or above 68 (Antananarivo Madagascar doesn’t seem so bad).
MapReduce excels at batch data processing, however it lags behind when it comes to repeat analysis and small feedback loops. The only way to reuse data between computations is to write it to an external storage system (a la HDFS). MapReduce writes out the contents of its Maps with each job — before the reduce step. This means each MapReduce job will complete a single task, defined at its onset.
If we wanted to do the above analysis, it would require three separate MapReduce Jobs:
- MaxTemperatureMapper, MaxTemperatureReducer, MaxTemperatureRunner
- MaxTemperatureByCityMapper, MaxTemperatureByCityReducer, MaxTemperatureByCityRunner
- MaxTemperatureByCityByDayMapper, MaxTemperatureByCityByDayReducer, MaxTemperatureByCityByDayRunner
It’s apparent how easily this can run amok.
Data sharing is slow in MapReduce due to the benefits of distributed file systems: replication, serialization, and most importantly disk IO. Many MapReduce applications can spend up to 90% of their time reading and writing from disk.
Having recognized the above problem, researchers set out to develop a specialized framework that could accomplish what MapReduce could not: in memory computation across a cluster of connected machines.
Spark: The Solution

Spark solves this problem for us. Spark provides us with tight feedback loops, and allows us to process multiple queries quickly, and with little overhead.
All 3 of the above Mappers can be embedded into the same spark job, outputting multiple results if desired. The lines above that are commented out could easily be used to set the correct key depending on our specific job requirements.
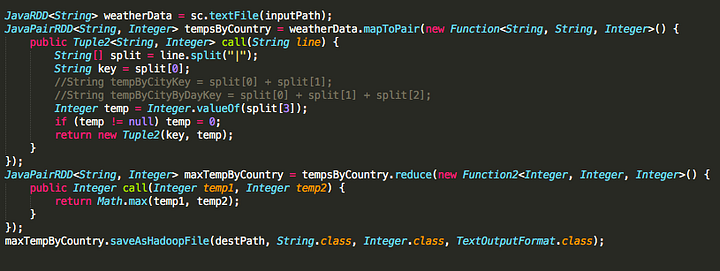
Spark Implementation of MaxTemperatureMapper using RDDs
Spark will also iterate up to 10x faster than MapReduce for comparable tasks as Spark operates entirely in memory — so it never has to write/read from disk, a generally slow and expensive operation.
Apache Spark is a wonderfully powerful tool for data analysis and transformation. If this post sparked an interest stay tuned: over the next several posts we’ll take an incremental deep-dive into the ins and outs of the Apache Spark Framework.


