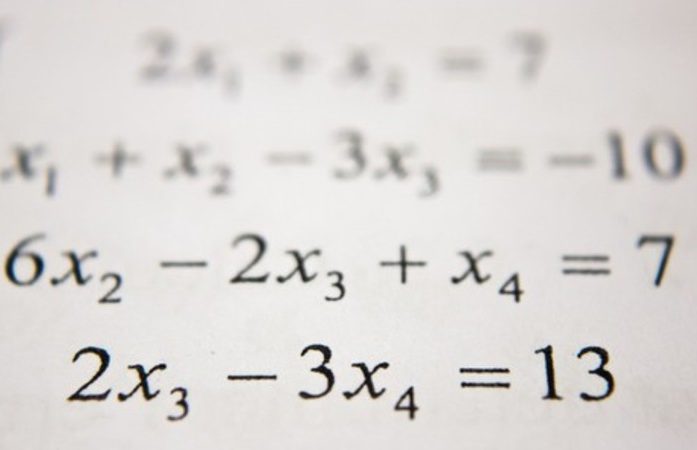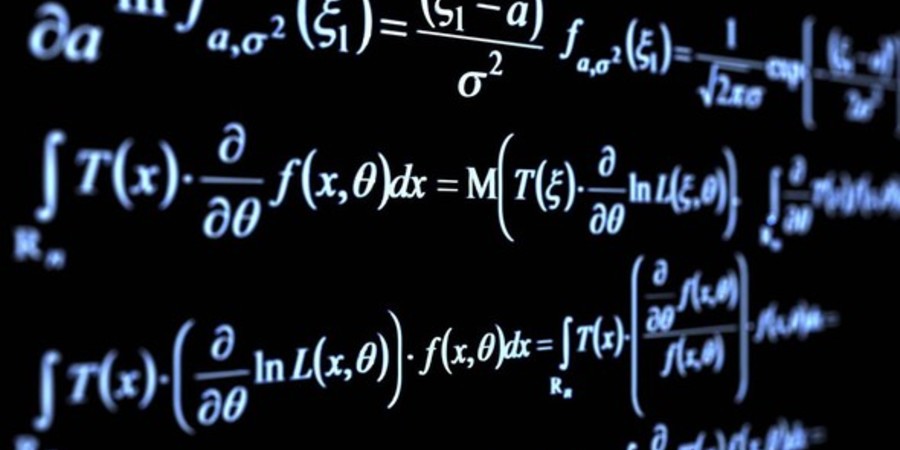For Natural Language Processing (NLP), conventionally, Recurrent Neural Networks (RNNs) build representations of each word in a sentence in a sequential manner, i.e., one word at a time. This post establishes links between Graph Neural Networks (GNNs) and Transformers. It will talk about the intuitions behind model architectures in the NLP and GNN communities, make connections using equations and figures, and discuss how we could work together to drive progress. It starts by talking about the purpose of model architectures–representation learning.