Ready to learn Internet of Things? Browse courses like IIoT Applications for Machine Learning developed by industry thought leaders and Experfy in Harvard Innovation Lab.
The internet of things is speeding from concept to reality, with sensors and smart connected devices feeding us a deluge of data 24/7. A study conducted by Cisco estimates that IoT devices will generate 600 zettabytes of data per year by 2020. Most of that data is likely to be generated by automotive, manufacturing, heavy industrial and energy sectors. Such massive growth in industrial IoT data suggests we’re about to enter a new industrial revolution where industries undergo as radical a transformation as that of the first industrial revolution. With the Industry 4.0 factory automation trend catching on, data-driven artificial intelligence promises to create cyber-physical systems that learn as they grow, predict failures before they impact performance, and connect factories and supply chains more efficiently than we could ever have imagined. In this brave new world, precise and timely data provided by low-cost, connected IoT sensors, is the coin of the realm, potentially reshaping entire industries and upsetting the balance of power between large incumbents and ambitious nimble startups.
But as valuable as this sensor data is, the challenges of achieving this utopian vision are often underestimated. A torrent of even the most precise and timely data will likely create more problems than it solves if a company is unprepared to handle it. The result is what I refer to as “digital exhaust.” The term digital exhaust can either refer to undesirable leakage of valuable (often personal) data that can be abused by bad actors using the internet or simply to data that goes to waste. This article discusses the latter use, data that never generates any value.
A 2015 report by the McKinsey Global Institute estimated that on an oil rig with 30,000 sensors “only 1% of the data are examined.” Another industry study suggests that only one-third of companies collecting IoT data were actually using it. So where does this unused data go? A large volume of IIoT data simply disappears milliseconds after it is created. It is created by sensors, examined locally (either by an IoT device or a gateway) and discarded because it is not considered valuable enough for retention. The majority of the rest goes into what I often think of as digital landfills — vast storage repositories where data is buried and quickly forgotten. Often the decisions about which data to discard, store and/or examine closely are driven by a short-term perspective of the value propositions for which the IIoT application was created. But that short-term perspective can place a company at a competitive disadvantage over a longer period. Large, archival data sets can make enormous contributions to developing effective analytic models that can be used for anomaly detection and predictive analytics.
To avoid IIoT digital exhaust and preserve the potential latent value of IIoT data, enterprises need to develop long-term IIoT data retention and governance policies that will ensure they can evolve and enrich their IoT value proposition over time and harness IIoT data as a strategic asset. While it is helpful for a business to have a clear strategic roadmap for the evolution of its IIoT applications, most organizations simply do not have the foresight to properly assess the full range of potential business opportunities for their IIoT data. These opportunities will eventually emerge over time. But by taking the time to carefully evaluate strategies for IIoT data retention, an enterprise can lay a good foundation upon which future value can be built.
So how can I avoid discarding data that might provide valuable insight or be monetizable, while still not storing everything? If storage cost and network bandwidth were unlimited, the answer would be easy. Simply sample sensor data at the highest resolution possible and send every sample over the network for archival storage. However, for many, IIoT applications with large numbers of sensors and high-frequency sampling, this approach is impractical. A balance must be struck between sampling data at a high enough rate to enable the responsiveness of real-time automated logic and preserving data at a low enough rate to be economically sustainable.
Is artificial intelligence the answer?
AI software algorithms that can emulate certain aspects of human cognition are becoming increasingly commonplace and accessible to open source communities. In recent years, the capabilities of these algorithms have improved to the point where they can approximate human performance in certain narrow tasks, such as image and speech recognition and language translation. They often exceed human performance in their ability to identify anomalies, patterns and correlation in certain data sets that are too large to be meaningfully evaluated using traditional analytic dashboards. And their ability to learn continually, while using that knowledge to make accurate and valuable predictions as data sets grow, increasingly impacts our daily lives. Whether it’s Amazon recommending books or movies, your bank’s fraud detection department giving you a call, or even self-driving cars now being tested — machine learning AI algorithms are transforming our world.
Many consider artificial intelligence critical to quickly obtaining valuable insight from IIoT data that might otherwise go to waste by surfacing critical operational anomalies, patterns and correlations. AI can also play a valuable role in identifying important data for retention. But employing AI in IIoT settings is not as simple as it sounds. Sure, AI cloud services (such as IBM’s Watson IoT and Microsoft’s Cortana) can be fed data and generate insight in a growing number of areas. However, IIoT poses some special challenges that make using AI to decide which (and how much) data to retain a non-trivial exercise.
The role of AI with fog computing
Companies facing the challenge of choosing between storing all raw IIoT sensor data generated or first blindly summarizing data in-flight (perhaps on an edge gateway) before transmission for long-term storage are often forced to choose the summarization approach. However, choosing the wrong summarization methodology can result in a loss of fidelity and missing meaningful events that could help improve your business. While consolidating data from many machines can allow the development of sophisticated analytic models, the ability to analyze and process time-critical data closest to where the data is generated can enhance the responsiveness and scalability of IIoT applications.
A major improvement over blind summarization would be to have time-critical complex analytic processing (such as algorithms for predictive failure analysis) operationalized on far-edge devices or gateways where they can process entire IoT data streams and respond as needed in real time. Less time-sensitive analytic intelligence and business logic can be centralized in the cloud and can use a summarized subset of the data. The AI algorithm can help to determine how much summarization is appropriate, based on a real-time view of the raw sensor data. This is where fog computing can play a role. Fog computing is a distributed computing architecture that emphasizes the use of far-edge intelligence for complex event processing. When AI is leveraged in a fog computing model, smarter real-time decisions (including decisions about when to preserve data) based on predictive intelligence can be made closest to where the data originates. However, this is not as easy to accomplish as it sounds. Edge devices often do not have sufficient computational and memory resources to accommodate high-performance execution of predictive models. While new fog computing devices capable of efficiently employing pre-trained AI models are now emerging, they may not have visibility into sufficiently large or diverse data sets to train sophisticated AI models. Obtaining large and diverse data sets still requires consolidation of data generated across many edge devices.
A practical compromise IoT architecture must first employ some centralized (cloud) aggregation and processing of raw IoT sensor data for training useful machine learning models, followed by far-edge execution and refinement of those models. In many industrial environments, this centralization will have to be on-premises (for both cost and security reasons), making private IoT data ingestion, processing and storage an important part of any IIoT architecture worth considering. But public IoT clouds can also play a role to enable sharing of insight across geographic and organizational boundaries (for example with distribution and supply chain partners). A multi-tiered architecture (involving far-edge, private cloud and public cloud) can provide an excellent balance between local responsiveness and consolidated machine learning, while maintaining privacy for proprietary data sets. Key to realizing such a multi-tiered architecture is the ability to employ ML at each tier and to dynamically adapt data retention and summarization policies in real time.
Adaptive federated ML
Federated ML (FML) is a technique where machine learning models can be operationalized and refined at the far edge of the network, while still contributing to the development of richer centralized machine learning models. Local refinements to far-edge models can be summarized and sent up one level for contribution to refinement of a consolidated model at the next tier. Far-edge devices across production lines within a factory can contribute to the development of a sophisticated factory-level model that consolidates learning from all related devices and production lines within that factory. Refinements to the factory-level model can be pushed up to an enterprise-wide model that incorporates learning across all factories.
Adaptive federated ML (AFML) takes FML a few steps further. First, as the centralized models evolve, they are pushed out to replace the models at lower tiers, allowing the entire system to learn. Second, when an uncharacterized anomaly is detected by the AI at the far-edge, the system adapts by uploading a cache of high-resolution raw data around the anomaly for archival and to allow for detailed analysis and characterization of the anomaly. Finally, these systems may also temporarily increase the sampling rate and/or reduce the summarization interval to provide a higher resolution view of the next occurrence of the anomaly.
Here’s an example of how an AFML approach works:
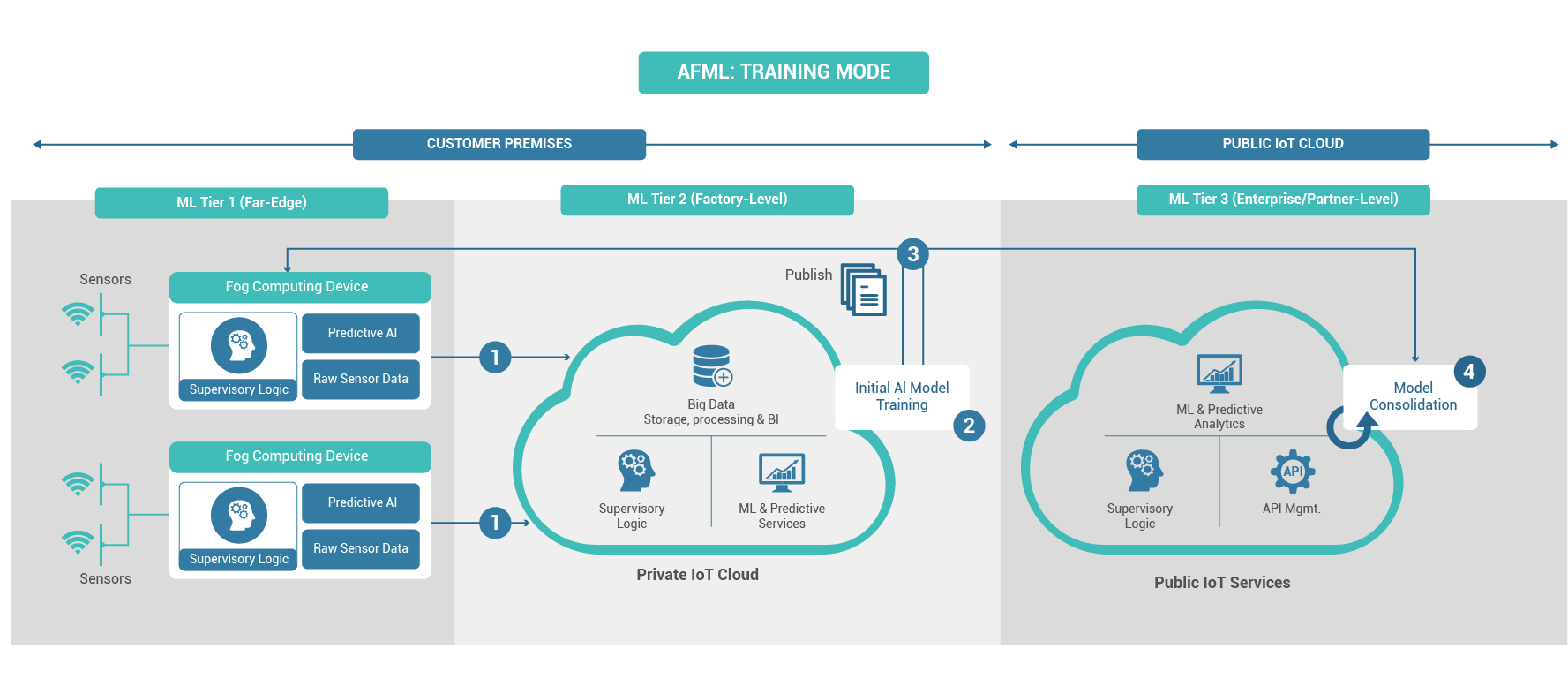
AFLM: INITIAL TRAINING MODE:
- All raw sensor data is sent from the IoT devices to centralized, on-premises private IoT storage for the time required to aggregate a sufficiently large data set for training of effective AI models.
- An on-premises big-data, cluster-computing environment is then used to train AI models for anomaly and predictive analysis.
- Once the models have been trained, they are pushed down to fog computing devices and up to the enterprise level for consolidation. Centralized aggregation of raw data ceases and the system switches to production mode.
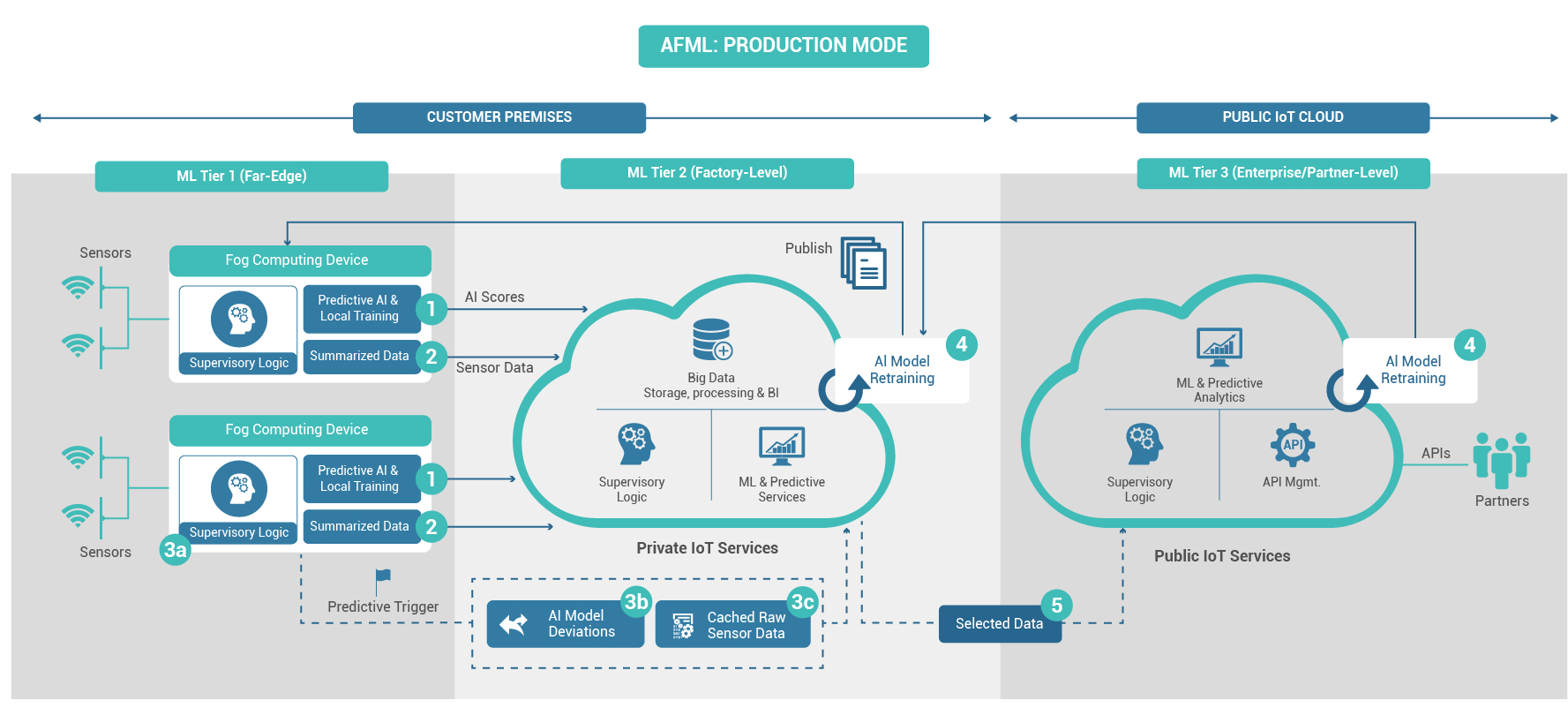
AFML: PRODUCTION MODE:
- Complex event processors on the fog computing devices use the AI model to analyze all data in real-time and provide their insight to local supervisory logic and the private cloud.
- When everything is nominal, only summarized data are forwarded to the centralized IoT cloud for archival.
- Whenever deviations from the model are flagged by the fog device AI, the supervisory logic does three things:
- Executes any local rules in place for that predicted failure
- Sends a summary of the model deviations to the on-premises IoT cloud (for updating of the consolidated model)
- If the exception is an uncharacterized anomaly, sends to the IoT cloud a cache of raw data that surrounds the anomaly
- A batch process at each IoT cloud tier routinely retrains the machine learning models (using model deviation data and raw data) and periodically pushes down the upgraded model to the lower tier.
- Finally, selected data subsets that can be used by partners are sent to the public cloud for further exposure.
So instead of simply choosing to blindly summarize IIoT data at the edge (generating massive data exhaust), complex predictive analytic models can be employed directly on the far-edge devices where all sensor data can be examined. These analytic models can not only inform timely local supervisory decisions, they can learn from data generated beyond their reach and can also dictate how much of the raw data is worth preserving centrally at any moment in time. With this approach, the entire system will react quickly and get smarter over time.
Choosing the right technologies for AFML
The key to making an AFML architecture work is selecting IoT and analytics tools that are designed with this model in mind. You will need an on-premises IoT and analytics cloud infrastructure that is efficient, flexible, scalable and modular. You will need to be able to easily orchestrate the interactions of your key architectural building blocks. The tools you select should allow you to easily adapt to the shifting needs of your business, allowing you to experiment and innovate.
Although we are starting to see a proliferation of IoT tools that can be used for developing various IIoT solutions, these tools are seldom well-integrated. Industrial enterprises typically look to systems integrators to bridge the gaps with custom software development. The result is often a confusing, inflexible, costly and unsupportable mishmash of technologies that have been loosely cobbled together.
Thankfully, a few IoT vendors are now beginning to build more fully-integrated IoT service creation and enrichment platforms (SCEPs), designed to support an AFML IIoT architecture. SCEPs allow complex IoT architectures, applications and orchestrations to be efficiently created and evolved with minimal programming and administrative effort. These next-generation IoT platforms will help companies eliminate IoT data exhaust and harness IIoT data for use as a strategic business asset.