5 missteps to avoid in your planning process
TL;DR — Amidst intentions of generating brilliant statistical analyses and breakthroughs in machine learning, don’t get tripped up by these five common mistakes in the Data Science planning process.
As a Federal consultant, I work with U.S. government agencies that conduct scientific research, support veterans, offer medical services, and maintain healthcare supply chains. Data Science can be a very important tool to help these teams advance their mission-driven work. I’m deeply invested in making sure we don’t waste time and energy on Data Science models that:
- Don’t go into production
- Don’t deliver actionable insights
- Don’t make someone’s life easier
Based on my experience, I’m sharing hard-won lessons about five missteps in the Data Science planning process — shortfalls that you can avoid if you follow these recommendations.
- Focus on Agility and Diversity
- Design for End Users’ Needs
- Plan for Productionization
- Understand Data Debt
- Pursue Options Beyond Machine Learning
Motivation
Just like the visible light spectrum, the work we do as Data Scientists constitutes a small portion of a broader range. A Data Scientist’s blindness to the data lifecycle can cause their machine learning project to fail.

The data lifecycle spans the full journey from planning to archiving. In large organizations, there may be a separate team that’s responsible for the DataOps work required to wrangle data into a workable shape for advanced analytics. There may be another team, DevSecOps, that conducts the work of putting models into production. In small organizations, the Data Scientists may be responsible for managing the end-to-end data pipeline.
Wherever your organization falls on this spectrum, it’s beneficial for Data Scientists to possess a clear-eyed view of the data lifecycle during the project planning process. In this article, I share five recommendations to support advanced analytics, machine learning, and model deployment across all the stages of project planning.
To start off, it’s helpful if data owners, consumers, and stakeholders share a basic level of data literacy. The Data Management Body of Knowledge is good reference material.
This 600+ pager continues to be exceedingly useful in my Data Science consulting work, and also useful in case anyone tries to fight me about the importance of data management.
#1 — Focus on Agility and Diversity
Agile methodology refers to a set of values and practices that enhance flexibility and accountability in software development. The four values of The Agile Manifesto:
- Individuals and Interactions over processes and tools
- Working Software over comprehensive documentation
- Customer Collaboration over contract negotiation
- Responding to Change over following a plan
What does a project planning discipline invented by 17 white men have to do with advancing diversity? Agile encourages frequent interaction with stakeholders that represent a diversity of functional roles across the organization.
Just as diversity from a business perspective leads to the production of better software — diversity in gender, race, ethnicity, and other personal characteristics can enhance creative problem solving.
Agile methodology values responsiveness to change. It requires fast iteration cycles that rely on trust and openness within a team. Meeting structures such as reviews and retrospectives can help teams to pause and reflect on whether they are promoting effective ways of working for all team members. In summary, Agile teams should leverage these practices and values with the aim of fully embracing the benefits of diversity.
In the words of Sian Lewis, a Lead Data Scientist at Booz Allen Hamilton and chair of the Professional Development Committee of the organization’s African American Network:
Countless studies have shown the more diverse your team, the more successful they’re going to be. I equate diversity with success. And I’m a human being — I enjoy success.
Read more about the impact of diversity on business outcomes:Diversity wins: How inclusion mattersDiversity wins is the third report in a McKinsey series investigating the business case for diversity, following Why…www.mckinsey.com
How to focus on agility and diversity:
- Design short iterations in your workflow and get stakeholder feedback with each iteration
- Actively seek diversity to promote different ways of thinking
- Create an environment of openness and trust via frequent conversations with your team about ways of working
#2 — Design for End Users’ Needs
The culture of Data Science encourages toy projects and Kaggle competitions to explore new ideas, sharpen skillsets, and hone dance battle skills. While these capabilities are important, Data Scientists also need to practice the crucial skill of project scoping. Struggle #2 refers to thinking that a Data Science initiative can succeed without a thorough investigation of end users’ needs at the outset.
The Data Scientist should take the approach of Human Centered Design to learn directly from the end users via interviews, then iteratively test and design a solution that takes their feedback into account. While the HCD work could be done by a separate team in a large organization, it’s best if the Data Scientist works directly with the users if at all possible.

In partnership with Google’s Next Billion User Initiative, the 99% Invisible team explored potential pitfalls of software development for new audiences around the world:
- Tech gone wrong — attempting to digitize the transaction ledger of small shop owners without first consulting on whether this was a problem the shop owners needed solved
- Tech done right — offering web-based education in concert with entertainment via movie vans
HCD principles can help produce joyous technology experiences, ensure a seamless handoff between machine learning application and human users, and mitigate negative feedback loopsto the greatest extent possible.
Read more about the impact of HCD on global access to technology.
How to design for the end users’ needs:
- Create an interview schedule early in the project
- Make sure the data product solves a problem for the end user
- Seek feedback on each iteration cycle
#3 — Plan for Productionization
87% of Data Science products never make it into production. The problems include:
- Unrealistic stakeholder expectations
- Failure to plan using agile methodology and HCD
- Lack of DevOps deployment skills like pruning and containerization
Add in a dash of Data Science tinkering (“I think I ran my Jupyter Notebook cells out of order”) — and it’s no surprise 9 out of 10 Data Science projects never see the light of day.Another AI Winter?How to deploy more ML solutions
Given that the only data product I’ve deployed thus far is this clustering-based Neighborhood Explorer dashboard, I’ll leave it to the more experienced to walk you through the deployment process. Rebecca Bilbro, Machine Learning Consultant at Unisys and co-creator of the Yellowbrick package, writes that:
Data Scientists should understand how to deploy and scale their own models…Overspecialization is generally a mistake.
She recommends courses and reading material on Kubernetes for Data Science. This container management tool represents the dominant force in cloud deployment. Containerization allows for app components to run in a variety of environments — e.g. other computers, servers, the cloud — and offers a lightweight alternative to virtual machines given that containers share resources with the host operating system rather than requiring a guest operating system.
In development, containers help overcome the challenges posed by multiple environments used by Data Scientists, Software Engineers, and DevOps practitioners. In production, containers deliver microservices to customers in response to network requests.
Of companies surveyed by the Cloud Native Computing Foundation, 84% used containers in production in 2019 and 78% employ Kubernetes to manage their deployments. Kubernetes provides provisioning, networking, load-balancing, security, and scaling — all the elements necessary to make container deployment simple, consistent, and scalable.
As containerization becomes increasingly mainstream, the approach opens new frontiers for data science model deployment. Scaling resources allows a model to better serve spikes in demand. Moreover, Kubernetes enables deployment on the edge — reducing latency, conserving bandwidth, improving privacy, and generally empowering smarter machine learning. Plus, it can manage deployment strategies such as A/B testing, blue-green deployments, and canary releases.
Read more from Caleb Kaiser on how to optimize your models for production: How to reduce the cost of machine learning inferenceA complete checklist for optimizing inference costst
How to plan for productionization:
- Familiarize yourself with deployment tools such as Heroku, Streamlit, Docker, and Kubernetes
- Designate resources for deployment during the planning phase, engaging DevOps expertise early
- Include specifications for monitoring and model redeployment in your deployment strategy
#4 — Understand Data Debt
If you discover data quality issues while conducting EDA and then silently proceed with your Data Science project, you are perpetuating your organization’s data debt. Per data strategist, John Ladley:
Enormous costs are incurred the longer you delay even the simplest and most basic levels of data management.
The term data debt provides quantification and rationale for weighing the costs associated with poor quality data. It’s based on the concept of tech debt, which refers to the impact of choosing the quick-and-dirty solution over a more thoughtful long-term fix.
Formal Data Governance documentation should address the problem of data debt by putting forward a plan to report data issues. This way, they can be rectified upstream. To quote John Ladley again:
Like all debts, data quality issues must be paid for eventually — either slowly over time (and with interest) or in a big chunk that pays off the debt.
Far better to resolve issues at their source than to apply a temporary fix at the analytics stage. An effective Data Quality Reporting Process could take the form of an intranet portal where issues can be sent to a specified Data Quality team (or at the very least, to the data source owner).
Insufficient action to remedy data debt represents Struggle #4 because Data Science practitioners typically don’t receive sufficient training in effective data management. In contrast to more established fields like Software Development and Data Engineering, there are few certification programs that are considered standard for data scientists. I’d really like to see more emphasis on formal training in data strategy.
Read more about how the best practices of software engineering can be applied to machine learning: 5 Must-Read Data Science Papers (and How to Use Them)Foundational ideas to keep you on top of the machine learning game.
How to avoid data debt:
- Connect the benefits of high-quality data and the risks of low-quality data to your organization’s strategic objectives
- Empower end users to report data quality issues to a designated team or to data source owners via a formal Data Quality Reporting Process
- Conduct a Data Quality Assessment that includes evaluating the quality of metadata
#5 — Pursue Options Beyond Machine Learning
We’ve discussed three key processes (Agile Methodology, Human Centered Design,and Data Quality Reporting) and two key teams (DataOps and DevSecOps) to support Data Science.
At the risk of beating you over the head with my 3 pound copy of the Data Management Body of Knowledge, there’s a lot of behind-the-scenes work that goes into setting up advanced analytics. The Data Science consultants at McKinsey agree, and caution that initiatives shouldn’t be approached with the mentality of a science project.
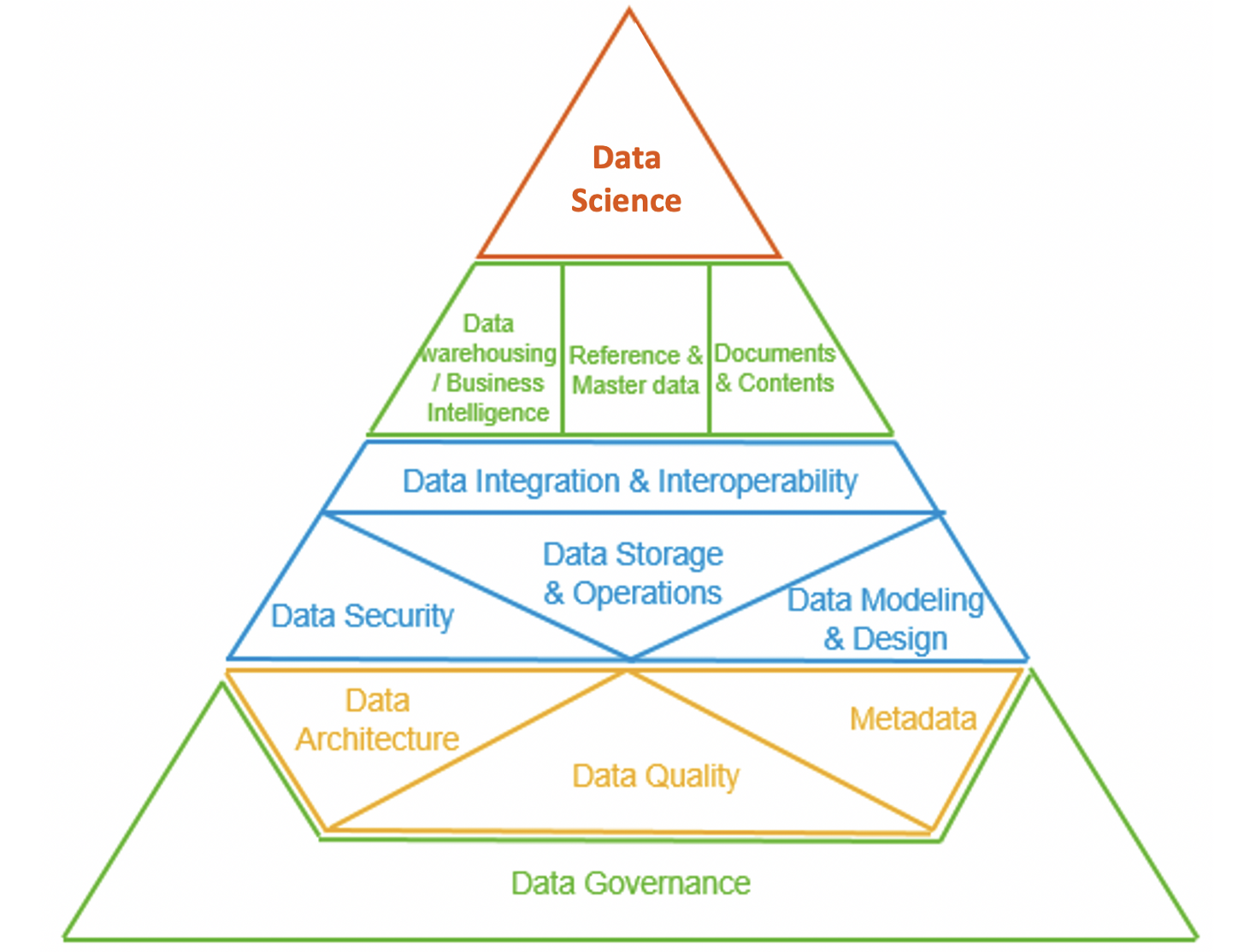
Like Maslow’s hierarchy of needs, Data Science actualization cannot be attained without first achieving the physiological and safety needs of Data Governance, Data Architecture, Data Quality, Metadata, etc. at the foundational levels of the Aiken Pyramid.
Before assuming that an organizational challenge needs to be solved with Data Science, it’s worth investigating whether that energy is better invested in a data quality improvement project followed by straightforward analytics. According to business intelligence expert, Rob Collie:
The most shocking thing is how far we have to go. Close to everyone we work with will say ‘we’re really primitive here. We’re way behind the curve.’
But everyone’s saying that. When I work at company X, I assume that every other company in the world has the basics done right. And they don’t.
Everyone is in the dark ages still.
Not all problems are Data Science problems. The organization may not have reached sufficient data maturity for advanced analytics. And that’s okay — as Rob puts it:
The next big thing: doing the basics right for the first time ever.
Data Science is part of the bigger ecosystem — a crucial component of business improvement and a core element of data-driven action. It represents the pinnacle of data-related activities. As such, it needs to be supported by robust data management practices.
How to pursue options beyond machine learning:
- Invest in your Data Engineering skills by learning SQL and understanding data modeling
- Invest in your ability to perform straightforward analytics and communicate the results for effective decision making
- Ensure Data Science proof of concepts are designed for deployment, not learning
Summary
Working in Data Science is as awesome as it sounds. There’s so much potential to make the world a better place by helping organizations leverage their data as a strategic asset. Avoiding these 5 potential struggles will help advance your problem solving capabilities to deliver effective data products



