
In the previous article, we reviewed several approaches to applying attention to vision models. We will continue our discussion, present a few additional vision models approaches in this article, and discuss their advantages over traditional approaches.
Stand-Alone Self Attention
Ramachandran et al. 2019 proposed an attention mechanism like the 2-D attention in Image Transformer [1]. A local region of pixels within a fixed spatial extent around the chosen pixel is used as a memory block for attention. Since the model doesn’t operate on all the pixels at the same time, it can work on high-resolution images without the need for down-sampling them to lower resolution in order to save computation.
Fig. 4. Stand-Alone Self Attention [1].
Figure 4 describes the Self Attention module. A memory block xab with a spatial extent of 3 pixels around pixel xij is chosen, and query qij is computed as the linear transformation of xij. Keys kab and values vab are calculated as linear transformations of xab. The parameters of the linear transformation are learnt during model training. Applying softmax on the dot product of the query qij and the key matrix kab results in the attention map. The attention map is further multiplied with the value matrix to obtain the final output yij.
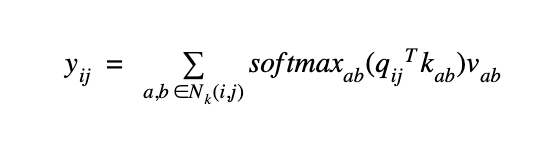
For encoding the relative positions of the pixels, the model uses 2-D relative distance between the pixel xij and the pixels in xab.
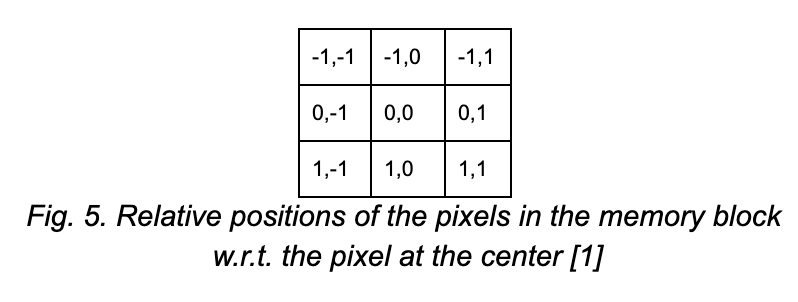
The row and column offsets are associated with an embedding, and they are concatenated to form ra-i,b-i. The final attention output is given as:
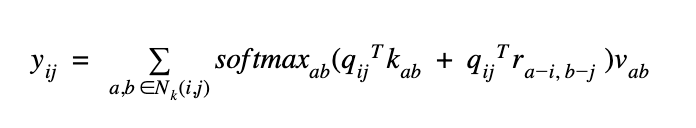
Hence, the model encodes both the content and the relative position of the pixels in its representation.
To address the computational challenge arising with handling very long sequences, Child et al. developed a sparse variant of attention [3]. This enabled the transformer model to handle different modalities such as text, image, and sound.
After observing the attention patterns at different layers in the transformers, the authors posit that most layers learn only a sparse structure, and few layers learn a dynamic attention map that stretches over the entire image. They introduce a two-dimensional decomposition of the attention matrix to learn diverse patterns, allowing the model to attend to all places in two steps. It’s approximately equal to the model creating the desired position while paying attention to each row and column.
The attention patterns as observed in layers 19 (left) and 36 (right). The attention head attends to pixels indicated in white for generating the next pixel. The pattern in layer 19 is highly regular, and it is a great candidate for applying sparse attention [2]
The first version is called strided attention. It is suitable for handling 2-D data, such as images. They also introduce a second version called fixed attention for handling 1-D data, such as text. Here, the model attends to a fixed column and the elements after the latest column element.
Overall, understanding the attention patterns and the sparsity in them helps to reduce redundant computation and learn long sequences efficiently.
Image GPT [4]
Image GPT is another example where a transformer model was successfully adopted for vision models tasks [4]. GPT-2 is a large transformer model that was successfully trained on language to generate coherent text [5]. Chen et al. trained the same model on pixel sequences to generate coherent image completions and samples. Although no knowledge of the 2-D structure was explicitly incorporated, the model can generate high-quality features that are comparable to the ones generated by top Convolution Networks in unsupervised settings.
Although not explicitly trained with labels, the model is still able to recognize object categories and perform well on image classification tasks. The model implicitly learns about image categories while it learns to generate diverse samples with clearly recognizable objects.
Since no image-specific knowledge is encoded into the architecture, the model requires a large amount of computation to achieve competitive performance in an unsupervised setting.
With enough scale and computation, a large language model, such as GPT-2, is shown to be capable of image generation tasks without explicitly encoding additional knowledge about the structure of the images.
Conclusion
In this series, we reviewed some of the works that applied attention to visual tasks. These models clearly demonstrate that there is a strong interest in moving away from domain-specific architectures to a homogenous learning solution that is suitable across different applications [6]. Attention-based transformer architecture shows great potential to evolve as a possible solution to bridge the gap between different domains. The architecture is constantly evolving to address the challenges and make it better suited for image and several other domains.
References:
[1] P. Ramachandran, N. Parmar, A. Vaswani, I. Bello, A. Levskaya, and J. Shlens, “Stand-Alone Self-Attention in Vision Models,” Jun. 2019, Accessed: Dec. 08, 2019. [Online]. Available: http://arxiv.org/abs/1906.05909.
[2] “Generative Modeling with Sparse Transformers.” https://openai.com/blog/sparse-transformer/ (accessed Sep. 19, 2021).
[3] R. Child, S. Gray, A. Radford, and I. Sutskever, “Generating Long Sequences with Sparse Transformers,” Apr. 2019, Accessed: Sep. 19, 2021. [Online]. Available: https://arxiv.org/abs/1904.10509v1.
[4] M. Chen et al., “Generative Pretraining from Pixels,” Accessed: Sep. 19, 2021. [Online]. Available: https://cdn.openai.com/papers/Generative_Pretraining_from_Pixels_V2.pdf.
[5] A. Radford, J. Wu, R. Child, D. Luan, D. Amodei, and I. Sutskever, “Language Models are Unsupervised Multitask Learners,” Accessed: Sep. 19, 2021. [Online]. Available: https://cdn.openai.com/better-language-models/language_models_are_unsupervised_multitask_learners.pdf.
[6] R. Bommasani et al., “On the Opportunities and Risks of Foundation Models,” Aug. 2021, Accessed: Sep. 20, 2021. [Online]. Available: https://arxiv.org/abs/2108.07258v2.



