As IT organizations grow, so does the size of their codebases and the complexity of their ever-changing developer toolchain. Engineering leaders have very limited visibility into the state of their codebases, software development processes, and teams. By applying modern data science and machine learning techniques to software development, large enterprises have the opportunity to significantly improve their software delivery performance and engineering effectiveness.
In the last few years, a number of large companies such as Google, Microsoft, Facebook and smaller companies such as Jetbrains and source{d} have been collaborating with academic researchers to lay the foundation for Machine Learning on Code.
What is Machine Learning on Code?
Machine Learning on Code (MLonCode) is a new interdisciplinary field of research related to Natural Language Processing, Programming Language Structure, and Social and History analysis such contributions graphs and commit time series. MLonCode aims to learn from large scale source code datasets in order to automatically perform software engineering tasks such as assisted code reviews, code deduplication, software expertise assessment, etc.

Why is MLonCode hard?
Some MLonCode problems require zero error rate, such as those related to code generation; automatic program repair is one particular example. A tiny, single misprediction may lead to the whole program’s compilation failure.
In some other cases, the error rate must be low enough. An ideal model should make as few mistakes as that the signal-to-noise ratio for the users – software developers – stays bearable and trustworthy. Thus the model can be used the same way as traditional static code analysis tools. A great example of this is best practices mining.
Finally, the vast majority of MLonCode problems are unsupervised or at most weakly supervised. It can be very costly to manually label datasets, so researchers typically have to develop correlated heuristics. For example, there are numerous similarity grouping tasks, such as showing similar developers or helping to compile teams based on areas of expertise. Our own experience in this topic lies in mining code formatting rules and applying them to fix faults, similarly to what linters do but completely unsupervised. There is a related academic competition to predict formatting problems called CodRep.
MLonCode problems include a variety of data mining tasks that may be trivial from the theoretical point of view but still challenging technically due to the scale or required attention to the details. Examples are code clone detection and similar developer clustering. Solutions of such problems are presented at the annual academic conference Mining Software Repositories.

While solving an MLonCode problem, one typically represents source code in one of the following ways:
A frequency dictionary (weighted bag-of-words, BOW). Examples: identifiers inside a function; graphlets in a file; dependencies of a repository. The frequencies can be weighted by TF-IDF. This representation is the simplest and the most scalable.
A sequential token stream (TS), which corresponds to the source code parsing sequence. That stream is often augmented with the links to the corresponding Abstract Syntax Tree nodes. This representation is friendly to conventional Natural Language Processing algorithms, including sequence-to-sequence deep learning models.
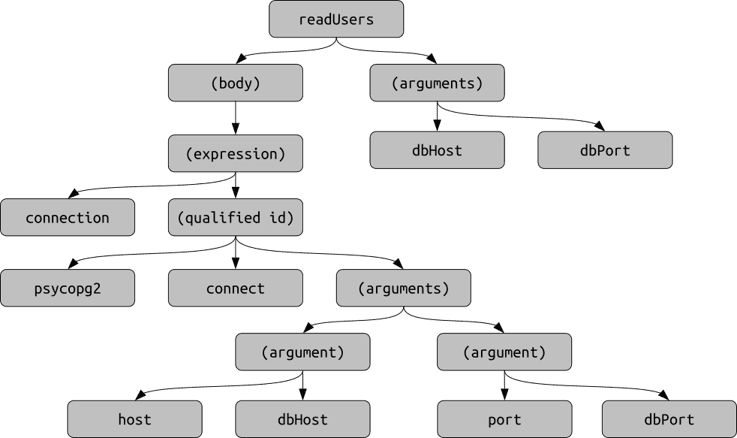
A tree, which naturally comes out from an Abstract Syntax Tree. We perform various transformations after, e.g. irreversible simplification or identifier posterization. This is the most powerful representation, and also the most difficult to work with. The relevant ML models include various graph embeddings and Gated Graph Neural Networks.

Many of the approaches to MLonCode problems ground on the so-called Naturalness Hypothesis (Hindle et.al.):
“Programming languages, in theory, are complex, flexible and powerful, but the programs that real people actually write are mostly simple and rather repetitive, and thus they have usefully predictable statistical properties that can be captured in statistical language models and leveraged for software engineering tasks.”This statement justifies the usefulness of Big Code: the more source code is analyzed, the stronger the statistical properties emphasized, and the better the achieved metrics of a trained machine learning model. The underlying relations are the same as in e.g. the current state-of-the-art Natural Language Processing models: XLNet, ULMFiT, etc. Likewise, universal MLonCode models can be trained and leveraged in downstream tasks.
There are such big code datasets. The current ultimate source is open source repositories on GitHub. There can be technical problems with cloning hundreds of thousands of Git repositories, so there are downstream datasets such as Public Git Archive, GHTorrent, and Software Heritage Graph.
Conclusion
As software continues to eat the world, we’re accumulating billions of lines of code, millions of applications built from great variety of programming languages, frameworks, and infrastructure. Not only can MLonCode help companies streamline their codebase and software delivery processes, but it also helps organizations better understand and manage their engineering talents. By treating software artifacts as data and applying modern data science and machine learning techniques to software engineering, organizations have a unique opportunity to gain a competitive edge.


