In this final article in a series on how small analytics teams can build a self-managed data library for effective data management, I will summarize the previous articles and show how to put it all together into a repeatable process.
A Data Library is Built on a Set of Principles for Data Management, not a Technology Stack
A data library does not require a specific technology or skill set. Rather, it is built on principles of good data management that are geared toward helping you to work more effectively. These principles are theoretical, but also actionable. The process you build should include whatever steps are necessary to implement your team’s data library principles.
A Data Library has an Informal Data Architecture, with “Ponds” and “Reservoirs”
It is easy to get caught up in how to name things. Naming conventions, including what I suggest, are less important than a purposeful architecture that supports collecting data in the ponds and preparing that data for analysis and reporting in the reservoirs. Your process should include, at a minimum, the work that is required to build automated data ponds, with the construction of the analytics and reporting reservoirs done on an as-needed basis.
A Data Library Balances Speed, Agility, and Cost, and is Built According to Priority
Creating a process with many steps can slow things down, but it ensures you do not cut any corners. The data library concept should help your team do things quickly in the future, but it takes time to build up the library infrastructure at the beginning. Prioritization is important so that if you are able to catalogue only one data source a quarter, you know you are working on the most important sources first.
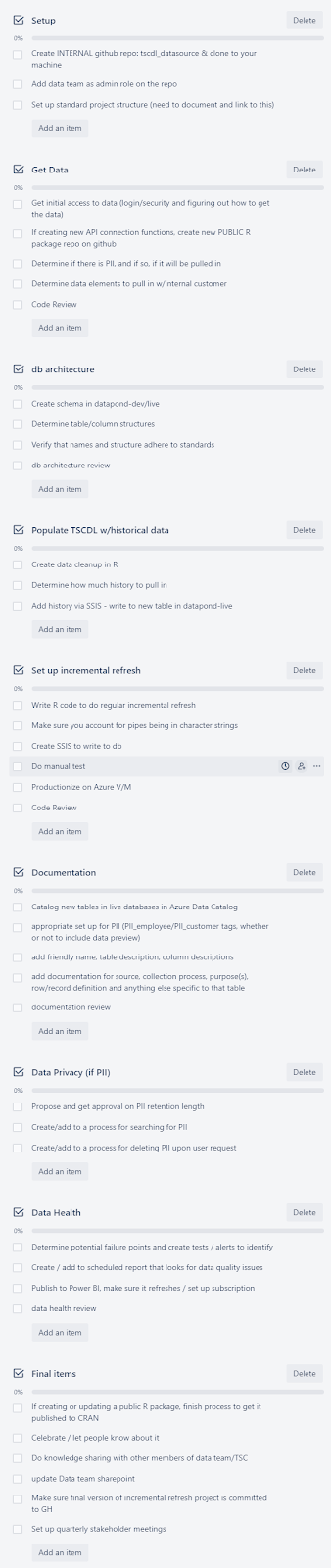
Building a Repeatable Process with a Checklist
To operationalize your data library, you will need to execute many small steps for each data source. Do your best to think of as many possible steps before you get started and then refine that list as you go. At TechSmith, our current list includes 39 steps. In a given project, some of these are unnecessary and others will be added. Starting with this list ensures that we will think about all of the important aspects and address each data library principle.
TechSmith’s checklist includes some final items that I have not mentioned previously. When you finish cataloguing a data source, you should celebrate! It is an accomplishment that will make your team more effective and enable you to better serve your stakeholders. Tell those stakeholders about it, give them examples of what can be done that was not possible before, and allow them to ideate. This process, along with a quarterly check-in with these stakeholders, leads to exciting new ideas.
Take the time to share knowledge with your team and others as well as doing project clean-up. This may include things such as committing all changes to a GitHub repo or standardizing a folder structure. If you are creating or contributing to open-source development, you should make that available to that community and publicize that it is available.